Building a Hallucination-Proof AI Assistant
AI hallucinations happen when a model confidently supplies information that isn’t real, misquoting regulations, inventing statistics, or citing studies that never existed. In low-stakes chat apps it’s an annoyance; in finance, healthcare, legal, or compliance it’s existential risk.
In this article, we will show you how to ship an assistant that handles hallucinations with layered safeguards and measurable benchmarks.

Why High-Stakes Domains Beat Up Chatbots
One wrong answer can trigger:
- regulatory fines or legal action
- patient harm or misdiagnosis
- financial losses and reputational damage
Assistants in these settings must parse dense rules, handle edge cases, and never guess. The error budget is effectively zero.
🔨 Do you understand the legal implications of AI in your business?
Three-Layer Defense Against Hallucination
| Layer | What It Does | Win | Loss | Examples |
| Retrieval-Augmented Generation (RAG) | Strengthens answers with authoritative ground truth. Pulls fresh text from trusted sources like regulatory sites, peer-reviewed papers, internal SOPs before composing an answer. | ✅ Grounds replies in evidence. | ❌ Fails if retrieval fetches the wrong document. | A company built a support bot that queries past tickets and knowledge bases via RAG/KG. It cut resolution time by ~29% and improved accuracy significantly (MRR +77%) |
| Guardrail Filter | Post-processes every answer: blocks missing citations, scope creep (e.g., medical or legal advice), and hand-wavy always/never claims. | ✅ Cuts risky output. | ❌ Over-filters if rules are sloppy. | An online banking assistant uses output guardrails to block advice on illegal investments, speculative statements like “always invest in X” and hate speech or inappropriate language. |
| Question Sanitizer | Rewrites the user prompt to remove ambiguity and hidden assumptions. | ✅ Sharper queries; cleaner answers. | ❌ Needs solid NLU to keep the chat natural. | Raw user input: |
Rule of thumb: Use all three, one patch isn’t enough.
Reference Architecture
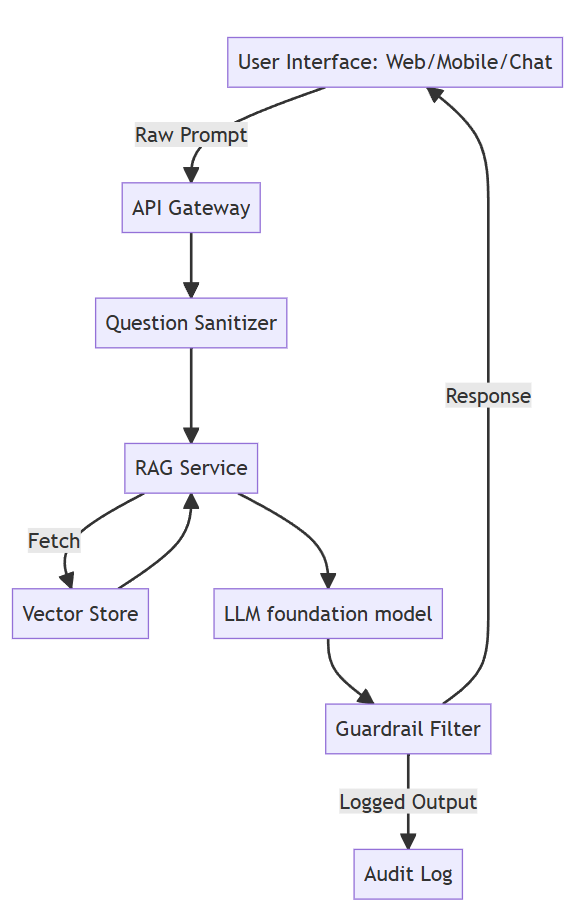
Components & Best Practices
- Vector Store & Embeddings Use top-tier embedding models benchmarked on MTEB (e.g., Snowflake Arctic, Jasper/Stella) for recall and speed. Keep vector DB options flexible: FAISS for self-hosting, Pinecone for scale, Azure Cognitive Search for ACLs.
- Retrieval Tuning Evaluate with metrics like recall@k, MRR, NDCG, and validate retriever+chunking combos per established frameworks.
- Foundation Model & Versioning For the latest AI models, head to LiveBench. Record the model hash in every run.
- Guardrails Use both rule-based and model-based approaches: OpenAI guardrails, Microsoft AutoGen, Nvidia Guardrails, or regex for citations/scope checks.
- Audit Logging Append-only logs (e.g., Cosmos, DynamoDB, Postgres WAL) should capture prompts, retrieval IDs, model info, and guardrail decisions.
Getting started with RAG
Here are some standout tutorials that explore the basics of retrieval augmented generation
1. “Code a simple RAG from scratch” (Hugging Face + Ollama)
Walks you through building a minimal RAG pipeline using Ollama, an open-source local model runner. Walks you through:
- Load text chunks
- Embed them with a HF model
- Index in a simple in-memory vector DB
- Use cosine similarity to fetch top-k context
- Generate answers via a local LLM
2. "Build a Retrieval Augmented Generation (RAG) App: Part 1” (LangChain)
The official LangChain tutorial that's heavy on clarity. It covers:
- Document loading, splitting, and indexing
- Vector store setup (Chroma/FAISS)
- Runtime retrieval + prompt-based generation via RetrievalQA chain Ideal for a lean and clean. (end-to-end RAG demo.)
3. “Build a RAG from scratch” (BuildRag / LlamaIndex)
No libraries, serious minimalism. Ideal for grasping core principles:
- Define a corpus
- Compute embeddings via OpenAI
- Use cosine similarity to pick top chunk
- Feed into prompt-controlled LLM
🔨 Do you handle AI Hallucinations the right way?
Measurement is Mandatory 🧪
Track these from Day 0:
- Exact‑Answer Accuracy (strict human match)
- Citation Coverage (every claim cited)
- Compliance Errors (rules/dosage mismatches)
- Hallucination Rate (uncited claims)
- Retrieval Miss Rate (monitor index drift or ACL failures)
Scaling Strategy
| Stage | Accuracy Target | Traffic | Human-in-Loop |
| Shadow Mode | ≥ 80 % observed | 0 % | 100 % offline review |
| Pilot/Augment | ≥ 80 % | ~5 % | Mandatory review |
| Limited Release | ≥ 95 % on top queries | ~25 % | Spot check |
| Full Automation | ≥ 99 % + zero critical | 100 % | Exception only |
Auto-fallback to human if metrics dip.
Domain Experts Are Non-Negotiable
- Source Curation – SMEs tag gold paragraphs; retriever ignores the rest.
- Prompt Reviews – experts catch edge cases outsiders miss.
- Error Triage – every bad answer is labeled why it failed, not just “wrong.”
Treat specialists as co-developers, not QA afterthoughts.
Key Takeaways
- Layer it on – RAG + sanitization + guardrail + hallucination detection.
- Measure everything – strict metrics are non-negotiable.
- Domain experts drive development, not just QA.
- Secure + log by default, with ACLs and audit trails.
- Scale with care – stay in human-in-the-loop until reliability is proven.
Nail these, and you’ll move from a flashy demo to a production-grade AI advisor that never makes up the rules.
Custom AI Development
Talk to our AI experts about your business today
Talk to us about your project
Connect with our Account Managers to discuss how we can help.