Rules to Better Clean Architecture - 16 Rules
SSW implements strict standards on all code produced. Implementing strict coding standards means your code can be easily read, modified, and tested. The Clean Architecture rules aim to have a strong .NET API, as a robust backend is more critical than a front end, whether in Angular, React, Vue, or Blazor.
Want to get more out of your software? Check SSW's Software Audit consulting page.
Clean Architecture is, at its core, about creating a Separation of Concerns, and building it in such a way that it becomes hard to violate this core principle. The outcome of this is to guide teams over time towards the pit of success.
This approach enables the development team to build a system in the same way that follows best practices, without the need for micromanagement. Having Clean Architecture enables changes to have isolated impact, and allows for the system to be easily extended and maintained.
This is the difference between a system that lasts 2 years, and a system that lasts 20 years.
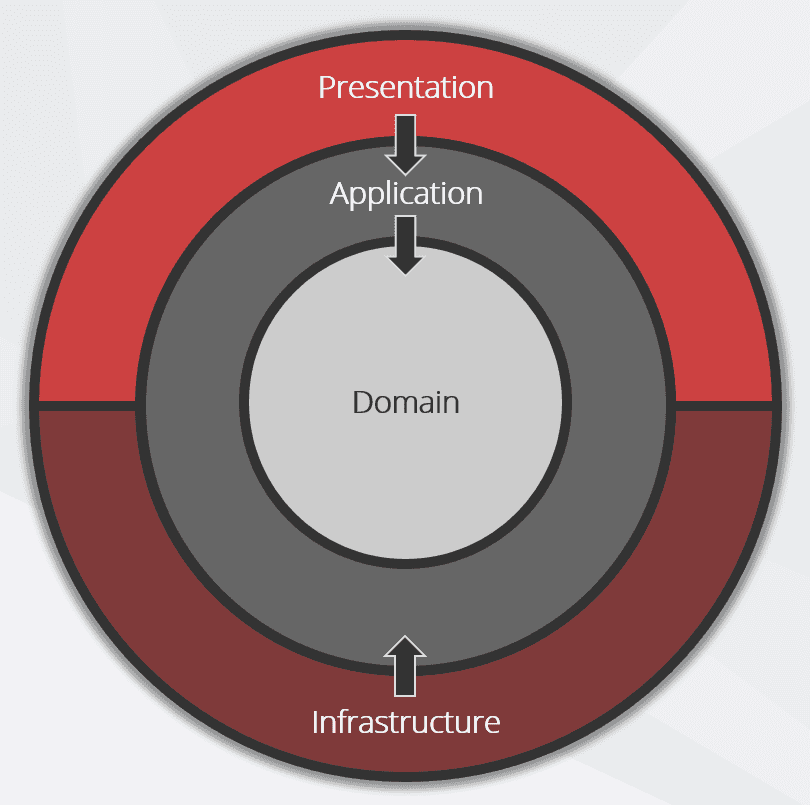
Figure: Onion view of Clean Architecture Note: While the design in the above figure only includes 3 circles, you may need more - just think of this as a starting point.
What is Clean Architecture?
Clean Architecture is a software design philosophy that emphasizes the separation of concerns among different parts of a software system. It structures an application in such a way that core business logic is isolated from user interface, database, and other external concerns, creating a system that is more modular, scalable, and maintainable.
Instead of having Core (Domain & Application layers) depend on data access and other infrastructure concerns, we invert these dependencies, therefore Infrastructure and Presentation depend on Core. This is achieved by adding abstractions, such as interfaces or abstract base classes, to the Application layer. Layers outside of Core, such as Infrastructure and Persistence, then implement these abstractions.
The 4 layers to Clean Architecture
Each layer has a specific purpose:
1 - Domain
The Domain layer contains the enterprise logic and types. This layer should not depend on anything outside of itself. This layer typically defines the models and data structures that represent the business entities and concepts.
Examples:
- Entities
- Value Objects (immutable objects that represent a single value or concept)
- Domain Events (something that has happened in the past)
2 - Application
The Application layer contains the business logic and types. This layer is dependent on the Domain layer, but not on anything outside of itself. This layer typically defines the application services that implement the use cases of the system. These services orchestrate the flow of data using the domain entities and types.
The Application layer only depends on abstractions, defined in interfaces, and these interfaces are implemented in outer layers. For example, persistence concerns (such as saving an item to a database) are defined only in terms of requirements; the persistence logic in the Infrastructure layer implements these requirements.
As the Presentation layer is external to Core, the Application layer has no dependency on any presentation concerns.
One example is obtaining information about the HTTP interaction (e.g. the user's ID or other information from an access token). This data is in the HttpContext, which is exposed in the Presentation layer, but not the Application layer. Rather than add a dependency on the Presentation layer, the Application layer can define its abstract requirements in an interface which can be implemented in the Presentation layer.
Examples:
- Application Services
- Use Cases/Features
- DTOs
3 - Infrastructure
The Infrastructure layer is where the external systems are interacted with. For example, you might setup a library to wrap a third party Web API, database, or identity provider. This layer is dependent on the Application Core. This layer defines the implementation of the abstractions defined in the Application layer.
This layer is important for keeping our application clean and testable. For general unit testing this layer is the one that is mocked out the most - therefore interfaces should make sense and be easy to mock.
Examples:
- Persistence
- Wrappers for interacting with External APIs
- Email/SMS
- Logging
- Authentication Provider
4 - Presentation
The Presentation layer is where the system is interacted with. This might be via a Web API, a GUI, or a CLI.
This layer is dependent on the Application layer & the Infrastructure layer.
The Presentation layer's sole responsibility is to interface with the means of external interaction and the Application Core. This layer should not contain any business logic, and should not be dependent on any external items.
The most common use case is a Web API - and it's implementation should define the API routes, its input & output models, using HTTP or other web protocols. The API should then call the Application layer, and either return an Application DTO or map to a Presentation ViewModel if required.
Principles
To achieve the this layering and separation of concerns, we need to follow some principles. To allow for the separation of concerns, we need to follow the Dependency Inversion Principle (DIP). This principle states that high-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.
What this means is that the Application Core should not depend on anything outside of itself - and we use interfaces in the Application or Infrastructure layer to achieve this.
Using a specific database class instead of depending on an interface.
Bad example - The application directly relies on the infrastructure. This makes the system harder to test and less flexible
Let the application depend on an interface, and have the infrastructure layer provide the implementation.
Good example - Use the Repository Pattern. This keeps things decoupled and easier to maintain
With this design, all dependencies must flow inwards. Core has no dependencies on any outside layers. Infrastructure, Persistence, and Presentation depend on Core, but not on one another.
Benefits
This results in an architecture and design that is:
- Independent of Frameworks - Core should not be dependent on external frameworks such as Entity Framework
- Testable - The logic within Core can be tested independently of anything external, such as UI, databases, servers. Without external dependencies, the tests are very simple to write.
- Independent of UI - It is easy to swap out the Web UI for a Console UI, or Angular for Vue. Logic is contained within Core, so changing the UI will not impact logic.
- Independent of Database - Initially you might choose SQL Server or Oracle, but soon we will all be switching to Cosmos DB
- Independent of any external agency - Core simply doesn't know anything about the outside world
References
There are many great resources for learning the principles of Clean Architecture, but a the best place to start is with Jason Taylor’s videos:
Video: Clean Architecture with ASP.NET Core 3.0 - Jason Taylor - NDC Sydney 2019 (1 hr)
Video: Clean Architecture with ASP.NET Core 2.1 | Jason Taylor (49 min)
Check out the Awesome Clean Architecture repo for a community driven up-to-date list of CA resources.
Further reading
Start with Robert C. Martin (aka ‘Uncle Bob’)’s blog post: The Clean Architecture.
Then, check out this book by Robert C. Martin should be anyone’s starting point for reading further:

Figure: Clean Architecture: A Craftsman's Guide to Software Structure and Design Also, this resource by Steve Smith is available as an online e-book and contains up-to-date specific examples for ASP.NET Core and Azure:

Figure: Architecting Modern Web Applications with ASP.NET Core and Microsoft Azure Courses
If you're building a Clean Architecture application, then the SSW Clean Architecture Template is the best way to get started.
Figure: The SSW Clean Architecture Solution Template The template is an implementation of Clean Architecture in a .NET Web API. It includes a full implementation of CA covering testing, validation and many other topics.
To set up this template, follow the steps in the project README | Getting Started.
The domain layer should be independent of data access concerns. The domain layer should only change when something within the domain changes, not when the data access technology changes. Doing so ensures that the system will be easier to maintain well into the future since changes to data access technologies won't impact the domain, and vice versa.
This is often a problem when building systems that leverage Entity Framework, as it's common for data annotations to be added to the domain model. Data annotations, such as the Required or MinLength attributes, support validation and help Entity Framework to map objects into the relational model. In the next example, data annotations are used within the domain model:

Bad Example: Domain is cluttered with data annotations As you can see in the above example, the domain is cluttered with data annotations. If the data access technology changes, we will likely need to change all entities as all entities will have data annotations. In the following example, we will remove the data annotations from the entity and instead use a special configuration type:


Good Example: Domain is lean, configuration for entity is contained within a separate configuration type This is a big improvement! Now the customer entity is lean, and the configuration can be added to the persistence layer, completely separate of the domain. Now the domain is independent of data access concerns.
Learn more about this approach by reading about self-contained configuration for code first.

Figure: Database implementation is a Infrastructure concern not a Domain concern It's common for business logic to be added directly to the presentation layer. When building ASP.NET MVC systems, this typically means that business logic is added to controllers as per the following example:

Figure: Bad example - Although this application clearly has repository and business logic layers, the logic that orchestrates these dependencies is in the ASP.NET Controller and is difficult to reuse The logic in the above controller cannot be reused, for example, by a new console application. This might be fine for trivial or small systems but would be a mistake for enterprise systems. It is important to ensure that logic such as this is independent of the UI so that the system will be easy to maintain now and well into the future. A great approach to solving this problem is to use the mediator pattern with CQRS.
CQRS stands for Command Query Responsibility Segregation. It's a pattern that I first heard described by Greg Young. At its heart is the notion that you can use a different model to update information than the model you use to read information...There's room for considerable variation here. The in-memory models may share the same database, in which case the database acts as the communication between the two models. However they may also use separate databases, effectively making the query-side's database into a real-time reporting database.Martin Fowler - https://martinfowler.com/bliki/CQRS.html
CQRS means clear separation between Commands (Write operations) and Queries (Read operations).CQRS can be used with complex architectures such as Event Sourcing but the concepts can also be applied to simpler applications with a single database.
MediatR is an open source .NET library by Jimmy Bogard that provides an elegant and powerful approach for writing CQRS, making it easier to write clean code.
For every command or query, you create a specific request class that explicitly defines the “input” required to invoke the operation.

Figure: (from MediatR docs) A Simple Request class Then the implementation of that command or query is implemented in a handler class. The handler class is instantiated by a Dependency Injection container – so can use any of the configured dependencies (Repositories, Entity Framework, services etc).

Figure: A handler class This approach brings many benefits:
- Each command or query represents an atomic, well-defined operation such as "Get My Order Details" (Query) or "Add Product X to My Order" (Command)
- In Web APIs, this encourages developers to keep logic out of controllers. The role of controllers becomes reduced to "Receive a request from the web and immediately dispatch to MediatR". This helps implement the "Thin controllers" rule. When logic is in a controller, the only way to invoke it is via web requests. Logic in a mediator handler can be invoked by any process that is able to build the appropriate request object, such as background workers, console programs or SignalR hubs
- Mediator also provides a simple pub/sub system allowing "side effects" to be explicitly implemented as additional, separate handlers. This is great for related or event-driven operations such as "Update the search index after a change to the product has been saved to database"
- Using a specific handler class for each operation means that there is a specific dependency configuration for each command or query
- Developers often implement interfaces and abstractions between the layers of their applications. Examples of this might include an IMessageService for sending emails or an IRepository interface to abstract database access. These techniques abstract specific external dependencies such as "How to save an order entity in the database" or "How to send an email message". We have witnessed many applications with clean, persistence-ignorant repository layers but then with messy spaghetti code on top for the actual business logic operations. MediatR commands and queries are better at abstracting and orchestrating higher-level operations such as "Complete my order" that may or may not use lower-level abstractions. Adopting MediatR encourages clean code from the top down and help developers "fall into the pit of success"
- Building even a simple app with this approach makes it easy to consider more advanced architectures such as event sourcing. You have clearly defined "What data can I get" and "What operations can I perform". You are then free to iterate on the best implementation to deliver the defined operations. MediatR handlers are easy to mock and unit test
- MediatR handlers are easy to mock and unit test
- The interface for MediatR handlers encourages the implementation of best-practice async methods with cancellation token support.
- MediatR introduces a pipeline behaviour system allowing custom to be injected around handler invocation. This is useful for implementing cross-cutting concerns such as logging, validation or caching

Figure: Good example - MediatR simplifies the dependencies injected into the controller. The incoming web request is simply mapped directly to a MediatR request that orchestrates all the logic for this operation. The implementation and dependencies needed to complete “GetItemForEdit” are free to change without needing to change the controller class When using MediatR within an ASP.NET Controller it is typical to see actions such as the following:

Figure: A Typical ASP.NET Controller using Mediator In the above example, the API contains a Create action that includes a CreateProductCommand parameter. This command is a request to create a new product, and the request is associated with an underlying request handler. The request is sent using MediatR with the method call _mediator.Send(command). MediatR will match the request to the associated request handler and return the response (if any). In a typical implementation, the request and request handler would be contained within separate files:
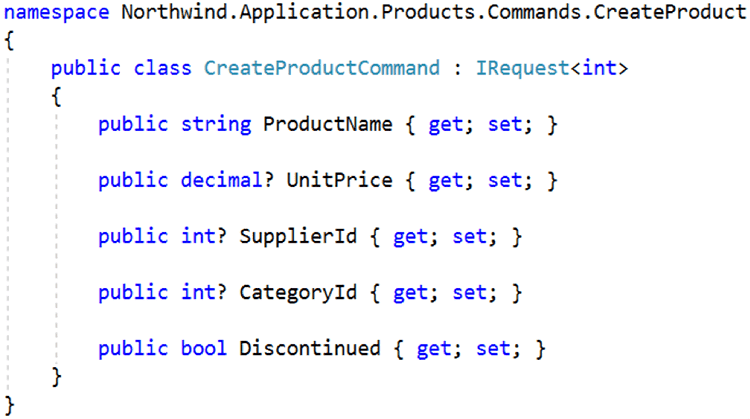
Figure: Bad Example - The request is contained within CreateProductCommand.cs 
Figure: Bad Example - The request handler is contained within CreateProductCommandHandler.cs In the above implementation, the request handler is cleanly separated from the request. However, this separation results in reducing discoverability of the handler. For example, a developer looking at the action in this first figure might be interested in the logic behind the command. So, they press F12 to go to the definition and can see the request (CreateProductCommand), but not the logic since it is contained within the request handler (CreateProductCommandHandler). The developer must then navigate to the handler using Solution Explorer or some keyboard wizardry. This is assuming that the developer is familiar with the design, and knows that there is an underlying request handler that contains the logic of interest. We can avoid these problems and improve discoverability by instead using the following approach:

Figure: Good Example - Nesting the Request Handler within the Request Improves Discoverability of Command and Associated Command Logic In the above example the request handler is nested within the request, there by improving the discoverability of the command and associated command logic.
Data Transfer Objects (DTOs) and View Models (VMs) are similar concepts, but the terms are not interchangeable. To make matters more confusing the term
ViewModelhas a special meaning inside the MVVM pattern.Do you understand the subtle difference between these terms?
What is a DTO?
A DTO is a type that is used to move data from one part of an application to another. This could be between a command and a service, or between an API and a UI. Typically, a DTO represents an entity or other resource.
Unlike regular classes, a DTO only includes data - not behaviour.
public class CarDto { public int Id { get; set; } public int MakeId { get; set; } public string Make { get; set; } public int ModelId { get; set; } public string Model { get; set; } public int Year { get; set; } public bool IsInsurable() { return this.Year > DateTime.Now.AddYears(-25).Year; } }Bad example - A DTO that encapsulates data but also includes behaviour (or logic in this case)
public class CarDto { public int Id { get; set; } public int MakeId { get; set; } public string Make { get; set; } public int ModelId { get; set; } public string Model { get; set; } public int Year { get; set; } }Good example - A DTO that encapsulates some data
What is a view model?
A view model (vm) is also a DTO, but it's a special kind of DTO. Rather than return data that corresponds to an entity or resource, it returns data that corresponds to a view. A view in this case is typically some part of a UI; although a view model could also be used to return a data structure that corresponds to the specific requirements of any part of an application. The distinction is that it represents the needs of the consumer, rather than the structure defined by the source.
This can be useful in situations where you have full control of both the consumer and provider. In a full-stack application this means both the UI and the API. In this case, you might have well-defined requirements for a view in the UI. Let's use a sales dashboard as an example; rather than have the dashboard make multiple calls to the API (say for the salespeople's names, their monthly figures, their targets, etc.), you can define a view model that returns all of the required data in one call.
What is a ViewModel?
In the MVVM pattern, the term ViewModel (VM) (in PascalCase) has a special meaning. A ViewModel provides functionality and state for a view (in this case, this is explicitly part of a UI), and therefore must contain logic as well as data. It also provides state, and acts as the glue between the UI (the View) and the service layer (the Model).
Learn more about the above concepts in the following Weekly Dev Tips podcasts:
In Clean Architecture, it is normally better to have a unique Data Transfer Object (DTO) for each endpoint or use case.
While sharing DTOs across multiple endpoints might seem like a way to save some code, it often leads to several problems:
- Unnecessary Data Transfer: Endpoints sending more data than what is actually needed, this can lead to performance issues.
- Increased Coupling: When multiple endpoints share the same DTO, a change required by one endpoint can inadvertently affect others.
- Developer Confusion: Developers will find it hard to understand which properties are relevant for a specific endpoint, leading to potential misuse or misunderstanding of the data structure.
By creating unique DTOs tailored to each endpoint's specific requirements, you ensure that:
- Endpoints only deal with the data they need.
- Performance is optimized by avoiding the transfer of superfluous data.
- Endpoints are decoupled, making them easier to develop, test, and maintain independently.
namespace Northwind.Trading.Application.Contracts.Models; public class OrderItemModel { public int OrderId { get; set; } public string CustomerId { get; set; } public DateTime OrderDate { get; set; } public decimal TotalAmount { get; set; } public OrderStatus Status { get; set; } /// <summary> /// Used for GetOrderListEndpoint. Ignore when updating /// </summary> public string? ShipFromCountry { get; set; } /// <summary> /// Used only for GetOrdersEndpoint. /// </summary> public DateTimeOffset ModifiedDateUtc { get; set; } /// <summary> /// Detailed list of order items. Only for GetOrderDetails. /// Not used for GetOrderList /// </summary> public List<OrderItemViewModel> OrderItems { get; set; } = []; }Figure: Bad example -
OrderViewModelis used for multiple purposes (e.g.,GetOrderList,GetOrderDetails,CreateOrder) and has accumulated many properties, making it hard to read and maintain.namespace Northwind.Trading.Application.Contracts.OrderQueries.Models; public class GetOrderListItemDto { public int OrderId { get; set; } public string CustomerId { get; set; } public DateTime OrderDate { get; set; } public decimal TotalAmount { get; set; } public OrderStatus Status { get; set; } }Figure: Good example - A simple
OrderSummaryDtodesigned specifically for an endpoint that lists orders.When building Web APIs, it is important to validate each request to ensure that it meets all expected pre-conditions. The system should process valid requests but return an error for any invalid requests. In the case of ASP.NET Controllers, such validation could be implemented as follows:
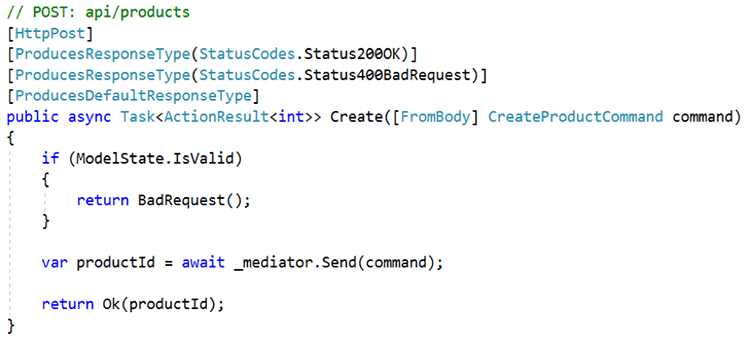
Figure: Bad Example - Managing Request Validation within the Controller In the above example, model state validation is used to ensure the request is validated before it is sent using MediatR. I am sure you are wondering - why is this a bad example? Because in the case of creating products, we want to validate every request to create a product, not just those that come through the Web API. For example, if we're creating products using a console application that invokes the command directly, we need to ensure that those requests are valid too. So clearly the responsibility for validating requests does not belong within the Web API, but rather in a deeper layer, ideally just before the request is actioned.
One approach to solving this problem is to move validation to the Application layer, validate immediately before the request is executed. In the case of the above example, this could be implemented as follows:
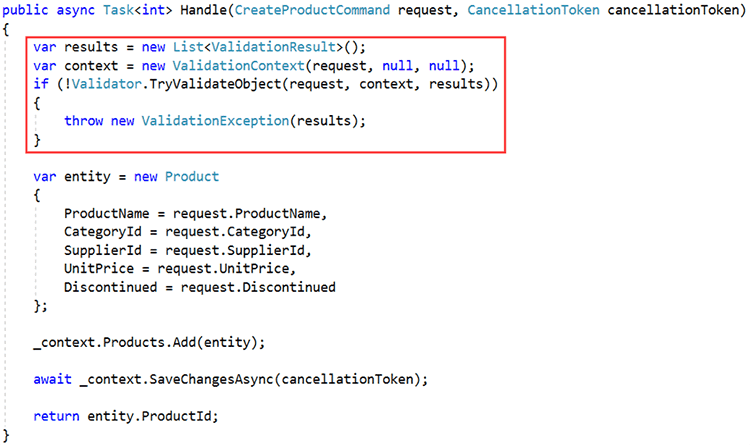
Figure: OK Example - Validation Handled Manually within Request Handler Ensuring All Requests are Validated The above implementation solves the problem. Whether the request originates from the Web API or a console app it will be validated before further processing occurs. However, the above code is boilerplate and will need to be repeated for each and every request that requires validation. And of course, it will only work if the developer remembers to include the validation check in the first place!
Fortunately, if you are following our recommendations and combining CQRS with MediatR you can solve this problem by incorporating the following behaviour into your MediatR pipeline:

Figure: Good Example - Automatically Validate All Requests By Using a MediatR Pipeline Behaviour This RequestValidationBehavior class will automatically validate all incoming requests and throw a ValidationException should the request be invalid. This is the best and easiest approach since existing requests, and new requests added later, will be automatically validated. This is possible through the power of MediatR pipeline behaviours. The documentation for MediatR includes a section on Behaviours; https://github.com/jbogard/MediatR/wiki/Behaviors. Review this documentation to understand how you can enhance your request handlers with behaviours and how to register pipeline behaviours.
The only step that remains is handle any validation exceptions. Within the console app, a try catch block will suffice. The action taken within the catch block will of course depend on requirements. Within the Web API, use an ExceptionFilterAttribute to catch these exceptions and convert them into a BadRequest result as follows:
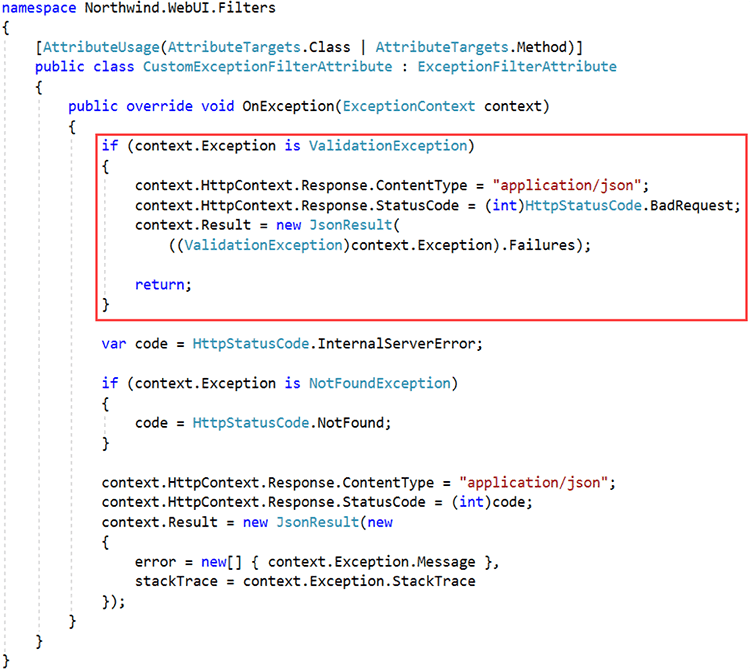
Figure: Good Example – Use an ExceptionFilterAttribute to Catch and Handle Exceptions within the Web API When defining a domain, entities are created and consist of properties and methods. The properties represent the internal state of the entity and the methods are the actions that can be performed. The properties typically use primitive types such as strings, numbers, dates, and so on.
As an example, consider an AD account. An AD Account consists of a domain name and username, e.g. SSW\Jason. It is a string so using the string type makes sense. Or does it?
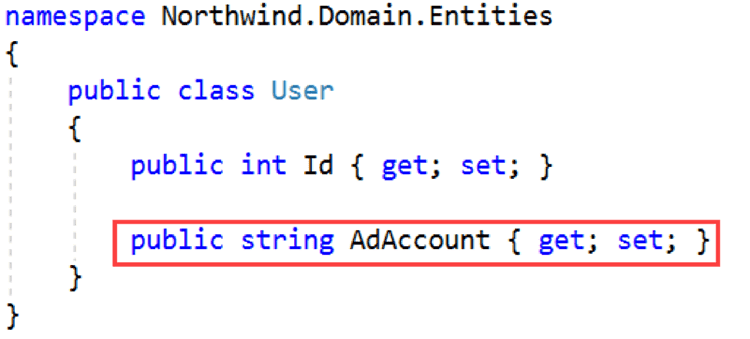
Figure: Bad Example - Storing an AD Account as a String (AD Account is a complex type) An AD Account is a complex type. Only certain strings are valid AD accounts. Sometimes you will want the string representation (SSW\Jason), sometimes you will need the domain name (SSW), and sometimes just the username (Jason). All of this requires logic and validation, and the logic and validation cannot be provided by the string primitive type. Clearly, what is required is a more complex type such as a value object.
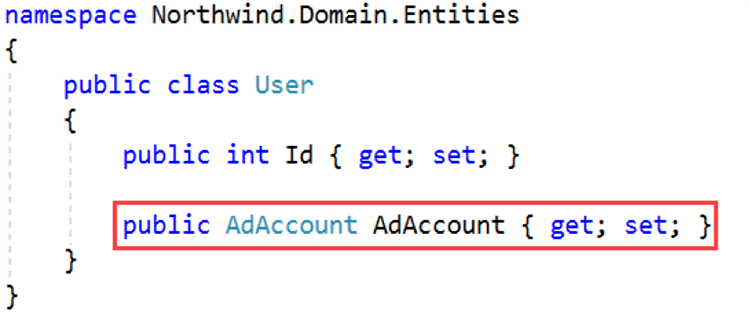
Figure: Good Example - Storing an AD Account as a Value Object to Support Logic and Validation The underlying implementation for the AdAccount class is as follows:

Figure: Good Example - Implementation of the AdAccount Value Object Supports Logic and Validation The AdAccount type is based on the ValueObject type.
Working with the AD accounts will now be easy. You can construct a new AdAccount with the factory method For as follows:

Figure: When use value The factory method For ensures only valid AD accounts can be constructed and for invalid AD account strings, exceptions are meaningful, i.e. AdAccountInvalidException rather than IndexOutOfRangeException .
Given an AdAccount named account, you can access:
- The domain name using; account.Domain
- The username using; account.Name
- The full account name using; account.ToString()
The value object also supports implicit and explicit conversion operators. You can:
- Implicitly convert from
AdAccount
to
string using; (string)account-
Explicitly convert from
stringto
AdAccount using; (AdAccount)"SSW\Jason"
If you're using Entity Framework Core, you should also configure the type as follows:
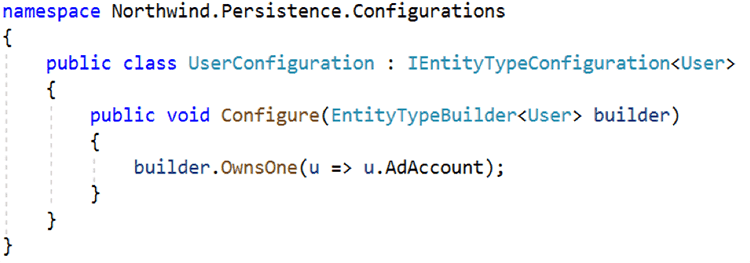
Figure: Using Entity Framework Core to Configure Value Objects as Owned Entity Types With the above configuration in place, EF Core will name the database columns for the properties of the owned entity type as AdAccount_Domain and AdAccount_Name. You can learn more about Owned Entity Types by reviewing the EF Core documentation.
Next time you are building an entity, consider carefully if the type you are defining is a primitive type or a complex type. Primitive types work well for storing simple state such as first name or order count, complex types work best when defining types that include complex logic or validation such as postal or email addresses. Using a value object to encapsulate logic and validation will simplify your overall design.
Developers often fall into the trap of using primitive types (
int,string,Guid) for entity identifiers when using Entity Framework (EF) because it is straight forward to simply add astringorintorGuidas theIDfield for an entity. The misuse of the primitive types lead to Primitive Obsession.Primitive Obsession refers to a code smell or anti-pattern where primitive data types (such as integers, strings, booleans, etc.) are excessively used to represent domain concepts, instead of creating dedicated classes to encapsulate those concepts.
Consider this example of Primitive Obsession:
public class Person { public Guid Id { get; set;} public string FirstName { get; set; } public string LastName { get; set; } public string EmailAddress { get; set; } /// ... more stuff } public class Customer { public Guid Id { get; set;} public string Name { get; set; } /// ... more stuff }The Guid
Idvalue of aPersonentity can easily be mistaken or used as the GuidIdvalue of aCustomerentity because there is no strong typing or encapsulation to prevent these two different entity ID types from being used interchangeably.Primitive Obsession can be witnessed on almost any domain concept, not just IDs (e.g. EmailAddress, PhoneNumber, Currency). To combat Primitive Obsession, we should consider creating meaningful and domain-specific classes to represent our concepts. By encapsulating related data and behavior into these classes, we can improve our code readability, maintainability, and flexibility. See Do you know when to use value objects? for examples of replacing data with Value Objects.
Using Strongly Typed IDs we can avoid the anti-pattern and clearly represent our domain entity specific identifiers.
Now with C# 9 (and later) we can use the
record(for one line declarations) or even therecord struct(for better performance - see below) type to declare strongly typed IDs very succinctly. Withrecords we no longer need to implement or override equality operators - they are automagically generated for us by the compiler.For example:
public readonly record struct PersonId(Guid Value); public readonly record struct CustomerId(Guid Value); public class Person : BaseEntity { public PersonId Id { get; set;} public string FirstName { get; set; } public string LastName { get; set; } public string EmailAddress { get; set; } /// ... more stuff } public class Customer : BaseEntity { public CustomerId Id { get; set;} public string Name { get; set; } /// ... more stuff }Viola! Now we have strongly typed IDs on our
PersonandCustomerentities and no way for anyone to get the values confused or misuse them.How do we configure EF to work with Strongly Typed IDs
To enable the correct serialization of Strongly Type IDs we need to add some configuration code to our EF Entities so that EF knows how to convert between the Primitive type and the Strongly Typed ID values.
Here is one way to specify the configuration:
public class PersonConfiguration : IEntityTypeConfiguration<Person> { public void Configure(EntityTypeBuilder<Person> builder) { // Primary Key builder.HasKey(e => e.Id); // Configuration for converting the `id` property To that will be stored in the database and From the primitive value (e.g. GUID, int, string) back into a strongly typed Id: builder.Property(e => e.Id) .HasConversion( // from Strong ID to Primitive value id => id.Value, // from Primitive value to Strong ID guidValue => new PersonId(guidValue)) // enable the primitive value to be auto-generated when adding (SaveChanges) new entities to the database (only works from EF Core 7 onwards) .ValueGeneratedOnAdd(); } }Another slightly cleaner looking approach could be to use a
ValueConverter:public class PersonConfiguration : IEntityTypeConfiguration<Person> { public void Configure(EntityTypeBuilder<Person> builder) { var converter = new ValueConverter<PersonId, Guid>( id => id.Value, guidValue => new PersonId(guid)); builder.HasKey(e => e.Id); builder.Property(e => e.Id) .HasConversion(converter) .ValueGeneratedOnAdd(); } }Check out the SSW Clean Architecture template for a few examples of Strongly Typed IDs in action.
Performance considerations
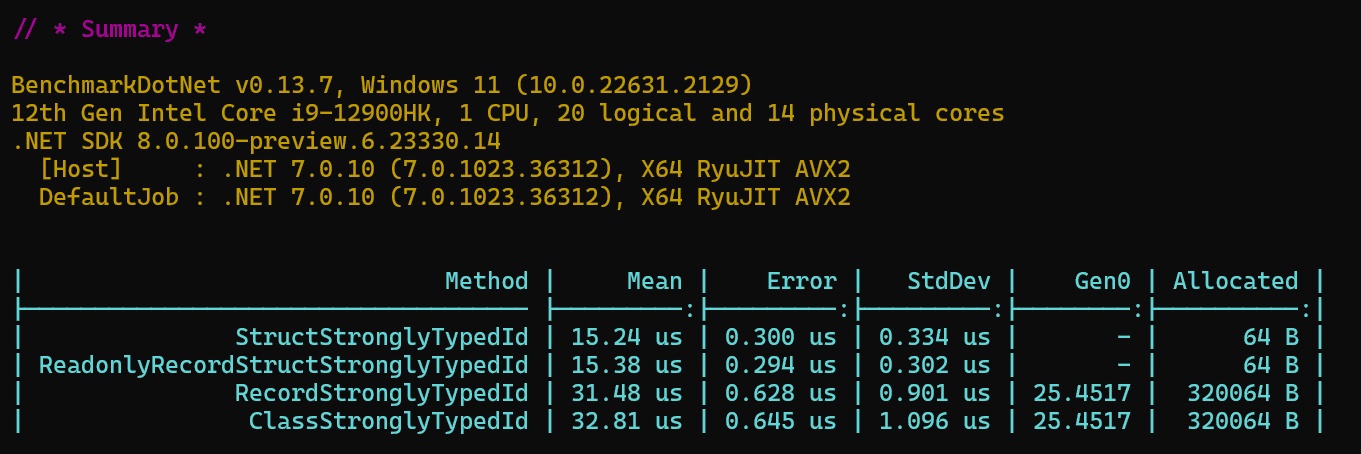
As mentioned earlier, we could use
recordorrecord structto succinctly describe our strongly typed IDs.However, when using
recordthere is a performance penalty we pay as pointed out by Dan Patrascu on his CodeWrinkles YouTube video Stop Using Records As Strongly Typed IDs!.Dan suggests to use
structorclassinstead because generating 10,000 strongly typed Ids is 4x faster compared to usingrecord.However,
classandstructare more verbose and require that we implement theEqualsandGetHashCodeoverrides manually!Dan unfortunately missed out a benchmark for
record struct. We wrote our own benchmark's similar to Dan's and as it turns outrecord structgives us the best of both worlds! We get the performance ofstructand the succinct one liner declarations ofrecordwithout needing to manually implement the equality checks.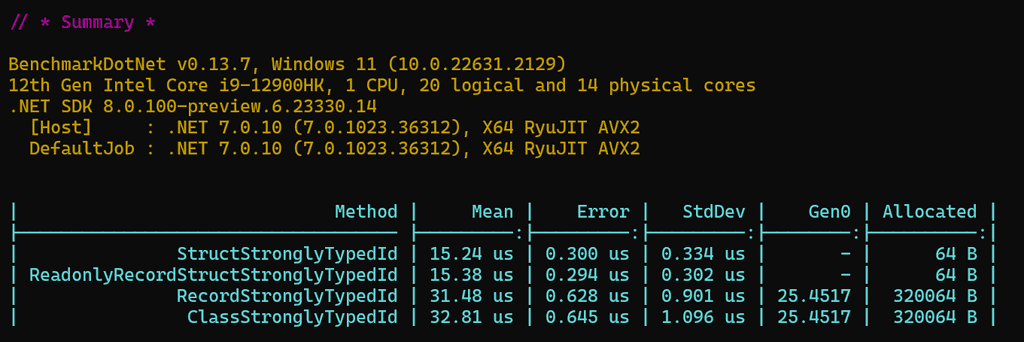
Benchmark results of various StronglyTyped ID constructs Check out William Liebenberg's StronglyTypeIdsBenchmark repo on GitHub for the benchmark results.
Summary
To add strongly typed IDs to our Entity Framework Entities we can utilize the
record structand add some simple entity configuration code to convert between primitive and strong type values.It is worth noting that
record's are immutable by default, butrecord struct's are not :(We can regain the immutability by adding the
readonlymodifier to our strongly typed ID declaration. With thereadonlykeyword the compiler will give us the same warnings at build time when any unwanted mutation to the ID value is made (or attempted to be made).So the ultimate programming construct for Strongly Typed IDs is
readonly record struct.public readonly record struct UserId(Guid Value);Domain Events and Integration Events are a concept primarily found in Domain-Driven Design (DDD) that can be applied in various other architectural patterns such as Clean Architecture.
Domain Events and Integration Events are powerful patterns improve decoupling and facilitate communication between different components of an application. They serve as a means of notification for important domain concepts that have occurred.
In Clean Architecture, Domain Events can be employed to enhance the communication between the
Domainlayer and other outer layers, such as theApplicationlayer orInfrastructurelayer. By raising Domain Events within theDomainlayer, we achieve loose coupling between different parts of the application while ensuring that the domain layer remains independent of other concerns.For an example implementation of DDD Domain and Integration events with Clean Architecture, check out this example project.
Here's a brief overview of how Domain Events fit into Clean Architecture:
DomainLayer: The domain layer, as discussed earlier, contains the domain model and business logic. When a significant event occurs within the domain, the relevant domain entity can raise a domain event without being concerned about what happens next.ApplicationLayer: The application layer, which orchestrates the flow of the application, is responsible for subscribing to Domain Events raised by the domain layer. When a domain event is raised, the application layer can react to it by initiating additional processes or triggering other actions in response to the event.InfrastructureLayer: The infrastructure layer is responsible for implementing the actual event handling mechanisms. It provides the infrastructure to publish and subscribe to Domain Events, and it ensures that the events are properly handled and dispatched to interested parties, such as external systems or other services.What are Domain Events
Domain Events are an integral part of the Domain Model.
Domain Events are immutable and can be considered as historical facts capturing something that occurred in the Domain process. They are meant to be a representation of past events and cannot be altered or disputed.
Domain Events are raised within the
DomainLayer of your application when an entity or aggregate makes a significant decision or undergoes a state change. The main purpose of Domain Events is to enable loose coupling and keep domain logic isolated from the application's infrastructure.For example, when an
Orderis placed, a domain event can be raised (e.g.OrderReceivedEvent) to notify other parts of the domain that need to react to this event, such as updating inventory or sending confirmation emails.Another example could be when the
Order'sStatuschanges fromOrderStatus.ReceivedtoOrderStatus.Processing, we can publish anOrderStatusChangedevent.Domain Events should not depend on external dependencies or external systems, adhering to the principles of the Domain Layer.
When publishing a domain event, the entire Entity or Aggregate can be included since the event's scope is confined to the current bounded context.
It is important to remember that the definition and behavior of a
Productin one bounded context might differ from another bounded context, like an e-commerce application product versus the product of a chemical reaction in a laboratory.In the
ApplicationLayer, Domain Events are typically in-process of the application. Any database side-effects are tracked as part of the current transaction of the original request, ensuring strong consistency in the response sent back to the user once the transaction is committed.What are Integration Events
Integration Events are used for communication between different bounded contexts (or microservices in a distributed system) and enable potentially long-running asynchronous operations like sending a large number of emails, generating thumbnail images, or performing additional business logic.
It is recommended that Integration Events should only be raised from the
Applicationlayer when the need for communication or coordination between different parts of the application arises. For example, after a specific use case (command / query) is handled successfully, theApplicationlayer might raise an Integration Event to notify other microservices or external systems about the outcome of that use case.If there is a strict domain requirement for Integration Events to be raised from the
Domainlayer then you need to be aware that you may inadvertently introduce coupling between domain logic and infrastructure concerns which could lead to violating one of the core principles of Clean Architecture (Dependency Inversion Principle)Integration Events are published after the original transaction completes and are typically dispatched through a Message Broker or Event Bus (e.g., Azure Service Bus, RabbitMQ, Redis PubSub, Dapr PubSub). To ensure reliability and consistency, systems often implement mechanisms like a Transactional Outbox.
Naming Events
When describing Domain or Integration Events, we commonly use a past-tense naming convention, such as
OrderCreated,UserRegistered,InvoiceConsolidated.It's essential to identify suitable events as not everything qualifies as an important event. For instance, "client walked into the store" or "chicken crossed the road" may not be appropriate for a Domain Event.
When to use Domain vs Integration Events
Use Domain Events within the
Domainlayer to decouple domain-specific logic and enable better maintainability and testability within the core of your application.Use Integration Events (preferably from the
Applicationlayer) when you need to communicate and coordinate between different parts of an application or distributed system (such as microservices), to achieve eventual consistency and loose coupling among services.The goal of a modern complex software project is to build software with the best software architecture and great cloud architecture. Software developers should be focusing on good code and good software architecture. Azure and AWS are big beasts and it should be a specialist responsibility.
Many projects for budget reasons, have the lead developer making cloud choices. This runs the risk of choosing the wrong services and baking in bad architecture. The associated code is hard and expensive to change, and also the monthly bill can be higher than needed.
The focus must be to build solid foundations and a rock-solid API. The reality is even 1 day of a Cloud Architect at the beginning of a project, can save $100K later on.
2 strong developers (say Solution Architect and Software Developer)
No Cloud Architect
No SpendOpsFigure: Bad example of a team for a new project
2 strong developers (say Solution Architect and Software Developer)
+ 1 Cloud Architect (say 1 day per week, or 1 day per fortnight, or even 1 day per month) after choosing the correct services, then looks after the 3 horsemen:- Load/Performance Testing
- Security choices
- SpendOps
Figure: Good example of a team for a new project
Problems that can happen without a Cloud Architect:
- Wrong tech chosen e.g. nobody wants to accidentally build and need to throw away
- Wrong DevOps e.g. using plain old ARM templates that are not easy to maintain
- Wrong Data story e.g. defaulting to SQL Server, rather than investigating other data options
- Wrong Compute model e.g. Choosing a fixed price, always-on, slow scaling WebAPI for sites that have unpredictable and large bursts of traffic
- Security e.g. this word should be enough
- Load/Performance e.g. not getting the performance to $ spend ratio right
Finally, at the end of a project, you should go through a "Go-Live Audit". The Cloud Architect should review and sign off that the project is good to go. They mostly check the 3 horsemen (load, security, and cost).
When writing a large scale enterprise application you want to make sure you only have to write it once. Choosing the right software architecture for your system is crucial for its long term success and maintainability. The right software architecture will allow your software application will scale too meet new requirements. Choosing the wrong software architecture can turn adding new features and maintaining your code into an increasingly frustrating exercise in futility.
Popular architectures
Here are some of the popular architectures and factors to consider when deciding the best fit for your project:
Clean Architecture
Clean Architecture emphasizes separation of concerns, making your system easier to maintain and scale. This architecture is designed to keep the business logic independent of the frameworks and tools, which helps in achieving a decoupled and testable codebase.
See more on Rules to Better Clean Architecture.
You can find our CA template on GitHub
Vertical Slice Architecture
Vertical Slice Architecture structures your system around features rather than technical layers. Each feature is implemented end-to-end, including UI/API, business logic, and data access. This approach improves maintainability and reduces the risk of breaking changes.
This modular approach to software development can introduce inexperienced teams to the idea of shipping features as functional units with no shared knowledge of the domain entities, infrastructure layer, or application layer within another subsystem, further preparing them for future development environments that may use Modular Monolith or Microservices Architecture.
See more on Rules to Better Vertical Slice Architecture
You can find our VSA template on GitHub
Modular Monolith
A Modular Monolith organizes the system into modules that encapsulate specific functionalities. While it runs as a single application, it retains some benefits of microservices, such as independent module development and testing. It’s a good middle-ground between a monolith and microservices.
See more on Rules to Better Modular Monoliths.
Microservices
Microservices architecture involves splitting the application into small, independently deployable services. Each service focuses on a specific business capability and can be developed, deployed, and scaled independently. This approach is beneficial for complex and large-scale applications with multiple teams working on different parts.
See more on Rules to Better Microservices.
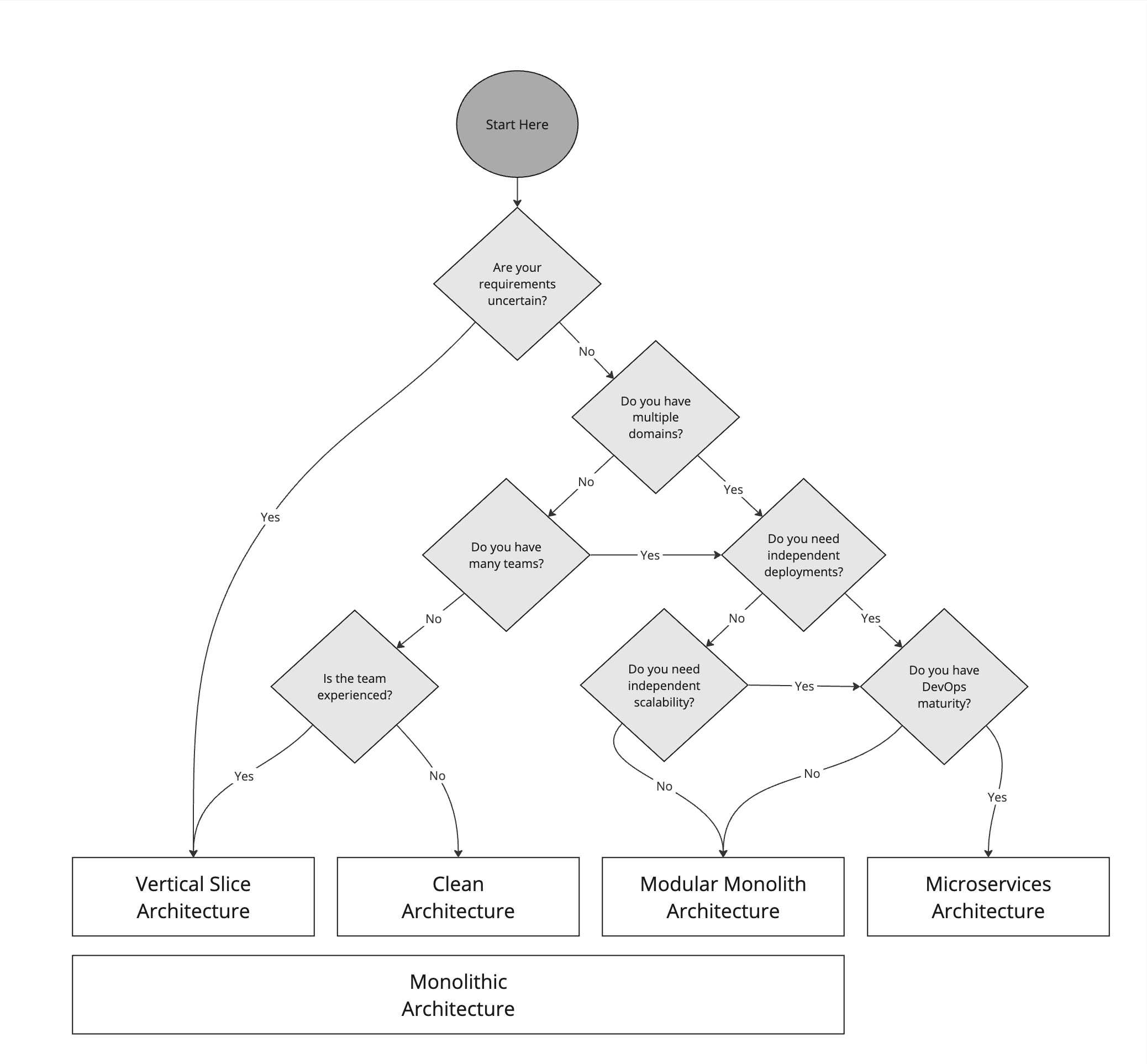
Architecture decision tree
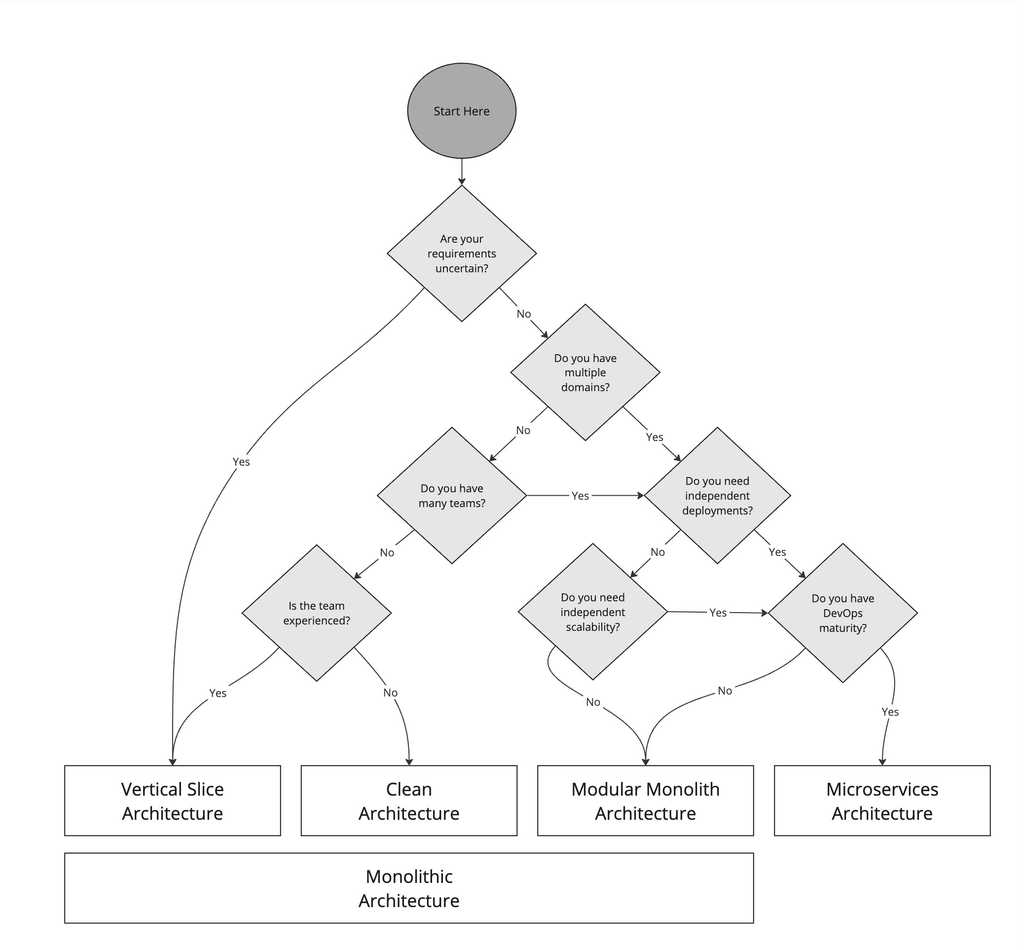
Figure: Architecture Decision Tree It's important to keep in mind that these architectures are not mutually exclusive.
Within a Modular Monolith Architecture, each module could be implemented using Clean Architecture or Vertical Slice Architecture. Similarly, a Microservices Architecture could use Clean Architecture or Vertical Slice Architecture within each service.
Also, from a pragmatic point of view a combination of Modular Monolith and Microservices might provide the best of both worlds. The majority of the system could be implemented as a Modular Monolith, with a few key services implemented as Microservices to provide scalability and flexibility where needed.
Factors to consider
- Are your requirements certain?
If requirements are likely to change, Clean Architecture or Vertical Slice Architecture can offer more flexibility. - Do you have multiple domains?
For applications with multiple domains, Modular Monoliths or Microservices can provide better separation and modularity. - Do you have many teams? If you have many teams, Microservices or Modular Monolith can help in reducing inter-team dependencies and allow parallel development.
- Do you need independent deployments? If independent deployments are necessary, Microservices is the best choice due to its isolated nature.
- Do you need independent scalability? Microservices allow each service to be scaled independently based on its specific needs, which can be more efficient and cost-effective.
- Do you have DevOps maturity? Microservices require a mature DevOps culture to manage deployments, monitoring, and scaling effectively. Without this, the overhead can be overwhelming.
- Is the team experienced? The complexity of Microservices can be challenging for less experienced teams. Vertical Slice Architecture although simple, has fewer guardrails when compared to Clean Architecture and can lead to a mess if not managed correctly. This leads to recommending Clean Architecture for less experienced teams that need more structure.
Examples
Here are some practical scenarios to illustrate the decision-making process:
Scenario 1: Startup with uncertain requirements
You are building an MVP with a small team and expect the requirements to evolve rapidly.
✅ Choice: Clean Architecture or Vertical Slice Architecture - These architectures offer flexibility and are easier to refactor as requirements change.
Scenario 2: Medium-sized business with limited DevOps maturity
You have a mid-sized team, and your organization is still developing its DevOps practices.
✅ Choice: Modular Monolith - A Modular Monolith provides some modularity benefits without the full complexity of Microservices, making it easier to manage with limited DevOps capabilities.
Scenario 3: Large enterprise with multiple domains and teams
You are developing a large-scale application with multiple business domains and have several teams working in parallel.
✅ Choice: Microservices - Microservices allow independent development, deployment, and scaling, which suits large and complex applications.
By carefully considering these factors and understanding the strengths and limitations of each architectural style, you can choose the best architecture for your system, ensuring a balance between flexibility, scalability, and maintainability.
- Are your requirements certain?
When developing software, ensuring that your code is maintainable, flexible, and readable is crucial. One effective way to achieve this is by implementing the Specification pattern. This pattern allows for clear and modular encapsulation of business rules and query criteria, promoting the separation of concerns and enhancing the overall quality of your code.
What Problem are we Solving here?
Let's take the example below of adding/removing items to/from a customer's order. When looking up the customer we need to include the current OrderItems and ensure the order is not complete. This logic is duplicated in both the AddItem and RemoveItem methods, which violates the DRY principle.
Even worse, if the logic changes, we need to update it in multiple places, increasing the risk of bugs and inconsistencies. Below we correctly check the orders status when adding items, but not when removing them which is a bug.
public class OrderService(ApplicationDbContext dbContext) { public async Task AddItem(Guid orderId, OrderItem item) { var order = dbContext.Orders .Include(o => o.OrderItems) .FirstOrDefault(o => o.Id == orderId && o.Status != OrderStatus.Complete); order.AddItem(item); await dbContext.SaveChangesAsync(); } public void RemoveItem(int age) { // Duplicated logic and bug introduced by not checking OrderStatus var order = dbContext.Orders .Include(o => o.OrderItems) .FirstOrDefault(o => o.Id == orderId); order.RemoveItem(item); await dbContext.SaveChangesAsync(); } }Figure: Bad example - Duplicated query logic to fetch the customer
What is the Specification Pattern?
The Specification pattern is a design pattern used to define business rules in a reusable and composable way. It encapsulates the logic of a business rule into a single unit, making it easy to test, reuse, and combine with other specifications.
Use Cases for the Specification Pattern
- Reusable Queries: Specifications can be used to define reusable query criteria for data access layers, making it easier to build complex queries.
- Validation Rules: Specifications can be used to define validation rules for input data, ensuring that it meets the required criteria.
- Encapsulating Business Rules: Specifications can encapsulate complex business rules in the Domain where most business logic should go.
- Repository Alternative: Specifications can be used as an alternative to repositories for querying data. Instead of encapsulating queries in repositories, you can encapsulate them in specifications.
Using the Specification Pattern
Steve Smith (aka ["Ardalis"])(https://github.com/ardalis) has created an excellent library called Ardalis.Specifications that integrates well with EF Core.
To use the Specification pattern, follow these steps:
-
Define the Specification:
public sealed class TeamByIdSpec : SingleResultSpecification<Team> { public TeamByIdSpec(TeamId teamId) { Query.Where(t => t.Id == teamId) .Include(t => t.Missions) .Include(t => t.Heroes); } } -
Use Specification:
var teamId = new TeamId(request.TeamId); var team = dbContext.Teams .WithSpecification(new TeamByIdSpec(teamId)) .FirstOrDefault();
For an end-to-end example of the specification pattern see the SSW.CleanArchitecture Template.
Good Example
Re-visiting the example above, we can apply the Specification pattern as follows:
public sealed class OrderByIdSpec : SingleResultSpecification<Order> { public IncompleteOrderByIdSpec(Guid orderId) { Query .Include(o => o.OrderItems) .Where(o => o.Id == orderId && o.Status != OrderStatus.Complete); } } public class OrderService(ApplicationDbContext dbContext) { public async Task AddItem(Guid orderId, OrderItem item) { var order = dbContext.Orders .WithSpecification(new OrderByIdSpec(orderIdorderId)) .FirstOrDefaultAsync(); order.AddItem(item); await dbContext.SaveChangesAsync(); } public void RemoveItem(int age) { var order = dbContext.Orders .WithSpecification(new IncompleteOrderByIdSpec(orderIdorderId)) .FirstOrDefaultAsync(); order.RemoveItem(item); await dbContext.SaveChangesAsync(); } }Figure: Good example - Specification used to keep Order query logic DRY
When using Domain-Centric architectures such as Clean Architecture, we need to decide where the business logic will go. There are two main approaches to this: Anemic Domain Model and Rich Domain Model. Understanding the differences between these two models is crucial for making informed decisions about your software architecture.
Anemic Domain Model
An Anemic Domain Model is characterized by:
- Property Bags: Entities are simple data containers with public getters and setters
- No Behavior: No logic or validation within the entities
Pros of Anemic Domain Model
- Good for simple or CRUD (Create, Read, Update and Delete) projects
- Easier to understand for developers new to the project
Cons of Anemic Domain Model
- Doesn’t scale well with complexity - complex logic can be duplicated across many places in the client code
- Difficult to maintain as the project grows - changes to logic need to be updated in multiple places
- Less readable code - Code related to an entity is scattered across multiple places
class Order { public int Id { get; set; } public DateTime OrderDate { get; set; } public decimal TotalAmount { get; set; } }
Figure: Example - Anemic model where the Order class is just a data container with no behavior.:::
Rich Domain Model
A Rich Domain Model, on the other hand, embeds business logic in the model (within Aggegates/Entities/Value Objects/Services). This approach makes the domain the heart of your system, as opposed to being database or UI-centric.
A Rich Domain Model is characterized by:
- Data and Behavior: Combines data and behavior (business logic and validation) in the same entity
- Encapsulation: Entities are responsible for maintaining their own state and enforcing invariants
Pros of Rich Domain Model
- Scales well with complexity - encapsulation (fundamental OOP principle) of the Domain model makes the calling client code simpler
- Easier to maintain - cohesion (fundamental OOP principle) of the Domain model means logic is closer to the data it applies to
- Encourages better testability - Domain model is easy to test in isolation
Cons of Rich Domain Model
- Steeper learning curve
- May require more initial setup and design
class Order { public int Id { get; private set; } public DateTime OrderDate { get; private set; } public decimal TotalAmount { get; private set; }
public Order(DateTime orderDate) { OrderDate = orderDate; TotalAmount = 0; } public void AddItem(decimal itemPrice) { if (itemPrice <= 0) { throw new ArgumentException("Item price must be greater than zero."); } TotalAmount += itemPrice; }}
Figure: Example - Rich model where the Order class encapsulates data and business logic.:::
In both cases the Application is still responsible for communicating with external systems via abstractions implemented in the Infrastructure Layer.
Choosing the Right Model
Projects with complex domains are much better suited to a Rich Domain model and Domain Driven Design (DDD) approach. DDD is not an all-or-nothing commitment; you can introduce the concepts gradually where they make sense in your application.
One side-effect of pushing logic into our Domain layer is that we can now start to write unit tests against our domain models. This is easy to do as our Domain is independent of our infrastructure or persistence layer.
Tips for Transitioning to a Rich Domain Model
- Start Small: Introduce DDD concepts gradually
- Focus on Key Areas: Identify the most complex parts of your domain and refactor them first
- Emphasize Testability: Take advantage of the isolated domain model to write comprehensive unit tests
- Iterate and Improve: Continuously refine your domain model as the project evolves
By understanding the differences between anemic and rich domain models, you can make informed decisions about your software architecture and ensure that your project scales effectively with complexity.
How does the Application Layer interact with the Model?
When using Clean Architecture we consider the Application Layer is part of the 'Core' of our system. It needs to interact with the Domain Layer for the system to function. This will happen in two slightly different ways depending on the underlying model.
- Anemic Domain Model: Application Layer follows the 'Transaction Script' pattern. The Application will contain all logic in the system. It will use the Domain Layer to update state, but will be in full control of the changes. There is no logic in the Domain and the entities become 'Data Access Objects'.
- Rich Domain Model: Application Layer becomes the 'Orchestrator' of the Domain. It is responsible for fetching the entities from the Persistence Layer, but will delegate to the Domain for any updates. The Domain Layer will be responsible for maintaining the state of the system and enforcing invariants.