Here are some of the typical things that all SQL Server DBAs and Database developers should know. These rules are above and beyond the most basic textbook recommendations of:
- Ensuring your databases are Normalized and in 3rd Normal Form
- Making sure you have primary keys, foreign keys and simple indexes to improve performance
- Making sure you Back up regularly
- Basic Naming conventions (see some of our object naming conventions)
- Minimizing result set sizes and data over the wire
View Database Coding Standard and Guideline.
Want to develop your SQL Server Database with SSW? Check SSW's Databases consulting page.
Imagine an e-commerce company called Northwind Traders, where thousands of products, multiple sellers, and millions of customers converge. In such a company, the importance of a well-designed database cannot be overstated.
Consider the scenario where a customer places an order only to encounter delays and frustration due to data inconsistencies that wrongly indicate an out-of-stock product. To mitigate such chaos, developers rely on relational database design principles, including normalization and entity-relationship diagrams (ERDs).
These concepts provide the foundation for a well-structured database with improved data integrity and reduced redundancy, ensuring smooth operations and customer satisfaction.
Database Normalization is a systematic approach to designing databases that reduces redundancy and avoids potential anomalies during data update, deletion, or insertion. This process involves organizing the columns (attributes) and tables (relations) of a database to ensure their dependencies are properly enforced by database integrity constraints.
Relational databases are complicated, and understanding the entire architecture of a database can be difficult when expressed solely in words. That's where Entity Relationship Diagrams (ERDs) come in. ERDs are a way of visualizing the relationships between different entities and their cardinality.
NULLs complicate your life. To avoid having to constantly differentiate between empty strings and NULLs, you should avoid storing NULLS if you can. Why? Well, what is wrong with this?
NULLs create difficulty in the middle-tier because you need to add further handling. So avoid them where you can, eg. For a Discount field, make the default 0 and don't allow NULLs.
Text in character columns (char, varchar, text, nchar, varchar, text) can start with spaces or empty lines which is usually data entry error.
The best way to avoid this issue is to handle whitespace in the middle-tier before it reaches the database.
This one is going to be a controversial one. But the bottom line is every now and then you want to do something and then you curse and wish your database didn't have identities. So why use them? Let's look at the problems first:
When users are deleting a lot of records as part of normal operations - they can and do make mistakes. Instead of the painful process of having to go to a backup to get these records, why not simply flag the records as IsDeleted?
SQL Server dates can range from the year 1900 up to the year 9999. However, certain date data in your database just wouldn't make any sense in the context of your business. For example, if your company started trading in 2015 you should not have any dates in your database before 2015 (unless you are tracking start dates of your clients, but this is an exception). An invoice date of 2013 wouldn't make sense at all.
There are two methods to avoid this:
Any DateTime fields must be converted to universal time from the application to the stored procedures when storing data into the database.
We can simplify dealing with datetime conversions by using a date and time API such as Noda TIme.
In many cases, there are legal requirements to audit all updates to financial records. In other cases, you will want to be able to track and undo deletes to your database. With the use of Temporal tables, this becomes much easier to manage.
We believe it is not good that use invalid characters (most of are Symbol characters, like ",;"/(", etc.) in object identifiers. Though it is legal, it is easily confused and probably cause an error during run script on these objects.
It is common to have a Contact Detail table to store your contact information such as phone numbers. Below is an example of a Contact Detail table and its related tables. This is bad because the PartyPhone table is too specific for a phone number and you have to add a new table to save an email or other contact information if this is needed in the future.
We recommend that you use a URL instead of an image in your database, this will make you:
- Avoid the size of your database increasing too quickly (which may bring a serial of problems, like performance, log and disk space, etc);
- Easy to validate and change the image.
Columns defined using the nchar and nvarchar datatypes can store any character defined by the Unicode Standard, which includes all of the characters defined in the various English and Non-English character sets. These datatypes take twice as much storage space per characters as non-Unicode data types.
Use
VARCHARinstead ofCHAR, unless your data is almost always of a fixed length, or is very short. For example, a Social Security/Tax File number which is always 9 characters. These situations are rare.SQL Server fits a whole row on a single page, and will never try to save space by splitting a row across two pages.
Running
DBCC SHOWCONTIGagainst tables shows that a table with fixed length columns takes up less pages of storage space to store rows of data.General rule is that the shorter the row length, the more rows you will fit on a page, and the smaller a table will be.
It allows you to save disk space and it means that any retrieval operation such as
SELECT COUNT(*) FROM, runs much quicker against the smaller table.Follow the below standards for tables and columns.
- All tables should have the following fields:
Field SQL Server Field Properties CreatedUtc datetime2 Allow Nulls=False Default=GETUTCDATE() CreatedUserId Foreign Key to Users table, Allow Nulls=False ModifiedUtc datetime2 Allow Nulls=False Default=GETUTCDATE() ModifiedUserId Foreign Key to Users table, Allow Nulls=False Concurrency rowversion Allow Nulls=False 1. Bit data type
Bit data from 0 to 1 (2 values only). Storage size is 1 byte.
Columns of type bit cannot have indexes on them.
Columns of type bit should be prefixed with "Is" or a "Should" ie.
IsInvoiceSent (y/n)orShouldInvoiceBeSent (y/n)you can tell easily which way the boolean is directed. See more information on naming conventions.This being said, fields of this type should generally be avoided because often a field like this can contain a date i.e.
DateInvoiceSent (Date/Time)is prefered overInvoiceSent (y/n). If a date is inappropriate then we still recommend an int field over a bit field anyway, because bits are a pain!Now, this is a controversial one. Which one do you use?
- A "Natural" (or "Intelligent") key is actual data
- Surname, FirstName, DateOfBirth
- An "Acquired Surrogate" (or "Artificial" or "System Generated") key is NOT derived from data eg. Autonumber
- eg. ClientID 1234
- eg. ClientID JSKDYF
- eg. ReceiptID 1234
- A "Derived Surrogate" (or "User Provided") key is indirectly derived from data eg. Autonumber
- eg. ClientID SSW (for SSW)
- eg. EmpID AJC (for Adam Jon Cogan)
- eg. ProdID CA (for Code Auditor)
- A "GUID" key automatically generated by SQL Server
When you specify a PRIMARY KEY constraint for a table, SQL Server enforces data uniqueness by creating a unique index for the primary key columns. This index also permits fast access to data when the primary key is used in queries. Although, strictly speaking, the primary key is not essential - we recommend all tables have a primary key (except tables that have a high volume of continuous transactions).
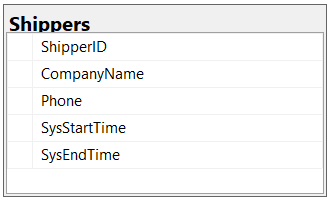
❌ Figure: Bad example - Table missing primarykey
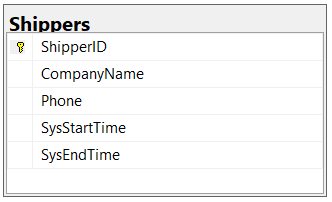
✅ Figure: Good example - Table with primary key
Legacy:
Especially, when you have a client like Access, it would help you to avoid the problems.
per page
1 - 20 of 65 itemsper page
1 - 20 of 65 items