The deployment of your schema is critical to your application. You should never get an error message reported from a user like:
"When I click the Save button on the product form it gives an ❌ error message about a missing field."
Bottom line is the customers' database schema should always be correct, should be managed automatically by the app and if it is not, you’re doing things wrong.
Use our great modern tools properly, and a schema problem will never bite you.
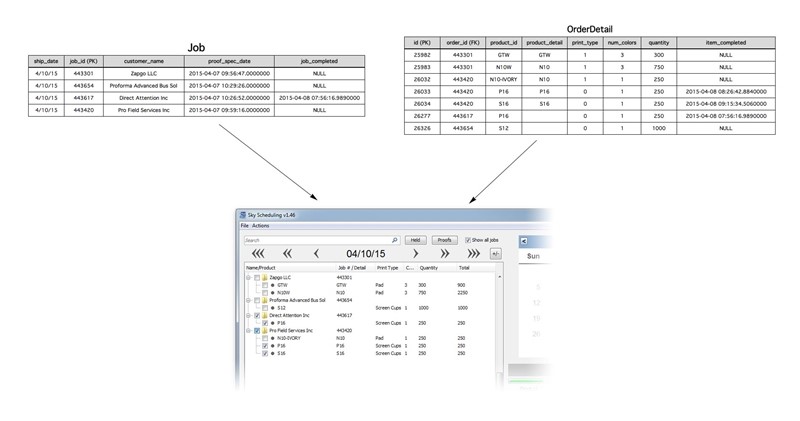
Figure: Schema Deployment
You have worked hard on the coding, got a "Test Pass" from the testers. Great! Now you have approval to deploy to production. Let's see some ways that allow for easy deployments.
In the fast-evolving world of software development, it's crucial for your database deployment process to be as efficient and reliable as your application updates. With the advent of .NET 10, there are several modern tools and methods that can help you achieve this seamlessly.
You have a website master right? This is the central point of contact if the site goes down. When developing an application, all members can code. However schema changes being done by many developers often can lead to trouble...
Do you dream to be a 'Schema Master' one day? If so you need to know what changes are low impact and what needs to be done with care. Take care when it involves existing data. Do you know what the hard ones are?
Let's look at examples of this increasing complexity (As per the Northwind sample database: Do you know the best sample applications?):
It is best practice to always include an applications version somewhere within the app, but do you also include the database version, its just as important!
Figure: Everyone shows the version number somewhere on their app
Let's see how to show the Database version:
Every time a change is made to your product's SQL Server Database, script out the change. Nowadays if you are using frameworks such as EF Core, this will most likely be handled for you with migrations. For older applications, you can use SQL Management Studio or Visual Studios, but every time you make changes you must save the change as a .sql script file so any alterations are scripted.
Everything you do on your database will be done at least three times (once on development, once for testing and once on production). Change control is one of the most important processes to ensuring a stable database system.
Let's see how its done.
SQL Compare is a good tool to find out the differences between two databases. It can help you answer the question "Is your database the same as mine?".
However, if you are doing this at the end of your release cycle, you have a problem. Your schema deployment process is broken...
An Application upgrade might not only include the .exe and .dll but the database changes. How to deploy these changes, manually or using tools to deploy?
Let's see the bad and good examples:
Many developers worry about Idempotency. They make sure that their scripts can run multiple times without it affecting the database, upon subsequent running of the script.
This usually involves a check at the start to see if the object exists or not. E.g. If this table exists, then don't create the table.
Seems popular, seems like a good idea, right? Wrong! And here is why.
Controlled Lookup Data is when data is tightly coupled to the application. If the data is not there, you have problems. So how do we check to see if data is still there?
Let's look at an example, of a combo that is populated with Controlled Lookup data (just 4 records)
Lookup data is data that you usually see in combo boxes. It may be a Customer Category, a Product Color or the Order Status. Usually this is defined by the user and the programmer does not care what or how many records they have. When the programmer relies on records being in the lookup table, it is called 'Controlled Lookup Data'.
So whenever you have special data, which is referenced in code you need to tread carefully by:
Scripting out a schema change is easy, worrying about data is not. "'Data motion" refers to a change in the meaning of data, which will require scripts which touch data and schema.
Let's look at an example:
Ideally you should be using computed columns as per Schema - Do you use computed columns rather than denormalized fields?
Many of the databases that SSW works with make use of denormalized fields. We believe this is with good reason. However, several precautions should be taken to ensure that the data held within these fields is reliable. This is particularly the case several applications are updating your denormalized data. To illustrate, let's say that we want to show all Customers with a calculated field totalling their order amount (ie Customer.OrderTotal).
With this example in mind, the main reasons we use denormalized fields are: