Rules to Better SQL Server Schema Deployment - 13 Rules
The deployment of your schema is critical to your application. You should never get an error message reported from a user like:
"When I click the Save button on the product form it gives an ❌ error message about a missing field."
Bottom line is the customers' database schema should always be correct, should be managed automatically by the app and if it is not, you’re doing things wrong.
Use our great modern tools properly, and a schema problem will never bite you.
You have worked hard on the coding, got a "Test Pass" from the testers. Great! Now you have approval to deploy to production. Let's see some ways that allow for easy deployments.
Modern Projects
If you are using Entity Framework Code First migrations this can be handled within your pipeline.

Figure: Using EF Migrations within your pipeline to apply these changes automatically Legacy Projects
With Visual Studio, deployment becomes easier and easier, you can choose different ways for different kinds of projects.
Web Clients
- Right-click "Publish" (recommended if you can directly connect)
OR - Right-click "Create Package"
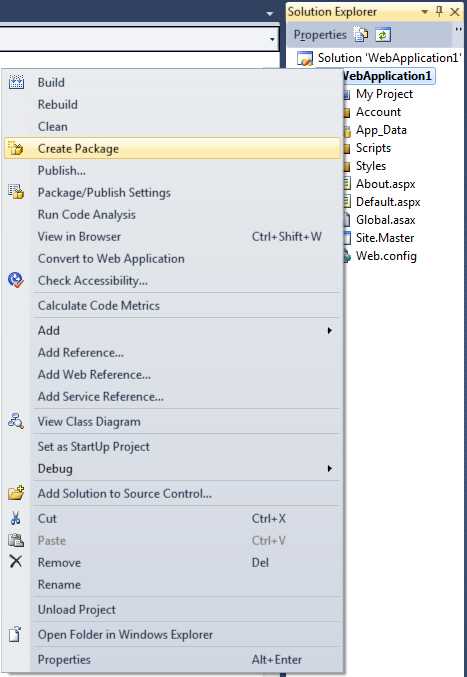
Figure: For a web app it is just one click Rich Clients
- Right-click "Publish" (recommended if you can use ClickOnce)
OR - Right-click "Create Setup" (Suggestion to Microsoft as menu doesn't exist)
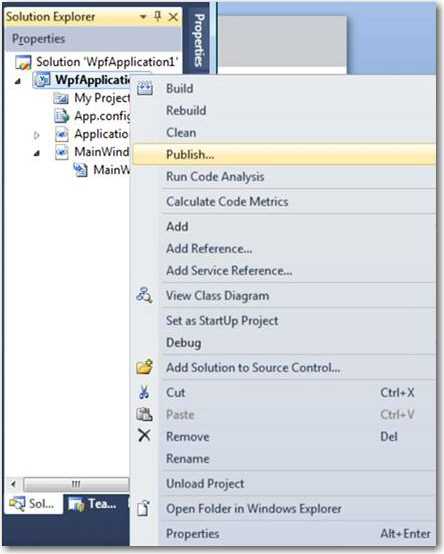
Figure: For a Windows clients it is also just one click Database
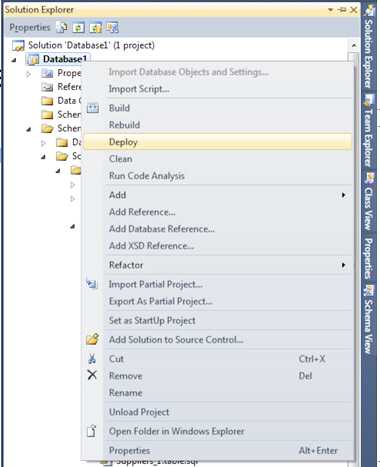
Figure: For the Database it is... well one click is what you need to aim for Now all this works beautifully first time, when there is no existing database... and no existing data to worry about. Now you have a reason to read the rest of the rules :-)
- Right-click "Publish" (recommended if you can directly connect)
In the fast-evolving world of software development, it's crucial for your database deployment process to be as efficient and reliable as your application updates. With the advent of .NET 8, there are several modern tools and methods that can help you achieve this seamlessly.
✅ Recommended Tools for Database Schema Updates
- Entity Framework Core Migrations: EF Core Migrations has become the de facto standard for managing database schema changes. It offers robust, integrated support for versioning and deploying database changes, making it the preferred choice for both new and existing projects.
- DAC Support For SQL Server Objects and Versions (.dacpac files): Still relevant for SQL Server database management, particularly in complex deployment scenarios.
❌ Not Recommended
These methods are outdated and lack the comprehensive features required for modern database schema management, With no ability to validate that the database hasn't been tampered with:
- SQL Deploy (This is the suggested tool if you are not using Entity Framework Code First)
- DbUp + SQL verify
- Navicat for MySQL
- DataGrip
- SQL Management Studio + OSQL (Free and roll your own)
- Visual Studio + SQL Server Data Tools (Formerly Data Dude) + Deploy (post-development model)
- Red Gate SQL Compare + Red Gate SQL Packager (post-development model)
You have a website master right? This is the central point of contact if the site goes down.When developing an application, all members can code. However schema changes being done by many developers often can lead to trouble...
To avoid this problem, only one person (the "Schema Master") or the release pipeline should have permissions to upgrade the database.
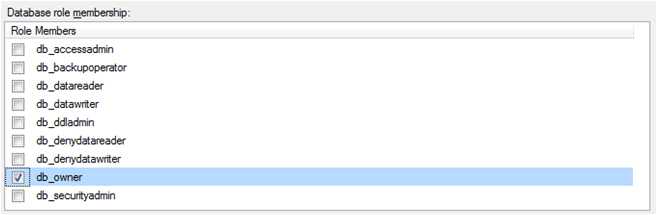
Figure: The db_owner role is granted for one person only – the "Schema Master" Who is the "Schema Master"? What do they do?

Figure: One person should be the 'Schema Master', on an average sized project (of 5-10 devs) If your project has a database, you need to select a "Schema Master". This is the one person who should review all modifications to the database. These include:
- Creating, Modifying and Deleting tables and columns
- Relationships
- Modify Controlled Lookup Data
The "Schema Master" in a development shop is often the lead programmer on the team. They are in charge of all database changes and scripts. Team members should still feel free to make changes, just get them double checked by the Schema Master.
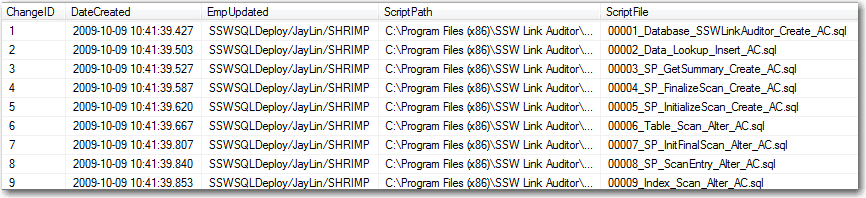
Figure: The Applications Database stores version info in a table called _zsVersion 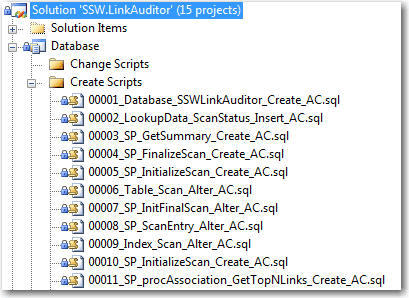
Figure: Only a "Schema Master" checks in the .sql files Do you dream to be a 'Schema Master' one day? If so you need to know what changes are low impact and what needs to be done with care. Take care when it involves existing data. Do you know what the hard ones are?
Let's look at examples of this increasing complexity (As per the Northwind sample database: Do you know the best sample applications?):
ALTER TABLE dbo.Employees ADD Gender bit NOT NULL GOFigure: Add a column (Easy)
ALTER TABLE dbo.Employees DROP COLUMN TitleOfCourtesy GOFigure: Delete a column (Easy)
EXECUTE sp_rename N'dbo.Employees.HireDate', N'Tmp_StartDate_1', 'COLUMN' GO EXECUTE sp_rename N'dbo.Employees.Tmp_StartDate_1', N'StartDate', 'COLUMN' GOFigure: Rename a column (Medium)
CREATE TABLE dbo.Tmp_Employees ( ... Gender char(2) NULL, ... ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] ... IF EXISTS(SELECT * FROM dbo.Employees) EXEC('INSERT INTO dbo.Tmp_Employees (..., Gender,...) SELECT ...,Gender ,... FROM dbo.Employees WITH (HOLDLOCK TABLOCKX) ') ... GO DROP TABLE dbo.Employees GO EXECUTE sp_rename N'dbo.Tmp_Employees', N'Employees', 'OBJECT' GOFigure: Change data type (Hard) e.g. Bit to Integer. The above is abbreviated, see the full .SQL file
CREATE TABLE dbo.Tmp_Employees ( ... Gender int NULL, ... ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] ... IF EXISTS(SELECT * FROM dbo.Employees) EXEC('INSERT INTO dbo.Tmp_Employees (..., Gender,...) SELECT ...,CASE Gender WHEN ''F'' THEN ''0'' WHEN ''M'' THEN ''1'' WHEN ''NA'' THEN ''2'' WHEN ''U'' THEN ''3'' ELSE ''-1'' END AS Gender ,... FROM dbo.Employees WITH (HOLDLOCK TABLOCKX) ') ... GO DROP TABLE dbo.Employees GO EXECUTE sp_rename N'dbo.Tmp_Employees', N'Employees', 'OBJECT' GOFigure: Change data type (Very Hard) e.g. Text to Integer. Text to Integer and data conversion requires "Data Motion Scripts". The above is abbreviated, see the full .SQL file
The point of this is to know that no tool out there, not Redgate's SQL Compare, not Visual Studio SQL Schema Compare (aka Data Dude), nor SSW's SQL Deploy will do this automagically for you. So you better understand that this stuff is delicate.
It is best practice to always include an applications version somewhere within the app, but do you also include the database version, its just as important!
Figure: Everyone shows the version number somewhere on their app Let's see how to show the Database version:
Modern Applications
These days frameworks handle database versioning for us, using code first migrations we can tell the application to automatically update the database when it starts up so its always at the latest version.
Legacy Applications
For legacy applications that aren't using Frameworks such as EF, keeping track of a databases version can be done in the following way.
Create a new table that will store the version info, this table is often called _zsDataVersion.
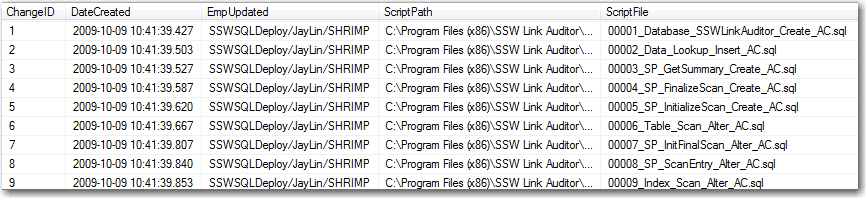
Figure: Example - SSW Link Auditor _zsDataVersion table For SSW Link Auditor this can be seen in the table status section.
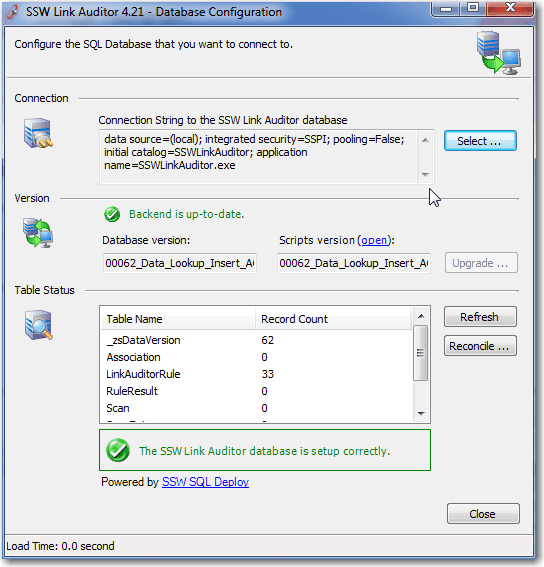
Figure: Example - SSW Link Auditor Database version is 62 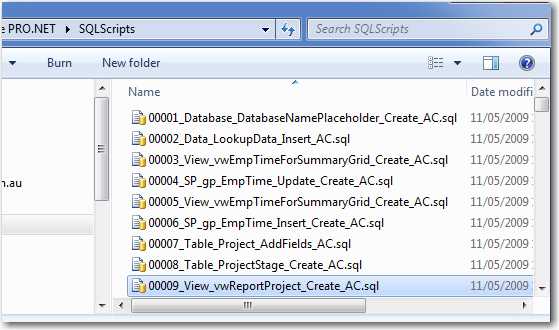
Figure: The Application keeps all the scripts in a folder called SQLScripts (this allows the application to upgrade itself and give the Reconciliation functionality) Every time a change is made to your product's SQL Server Database, script out the change.Nowadays if you are using frameworks such as EF Core, this will most likely be handled for you with migrations. For older applications, you can use SQL Management Studio or Visual Studios, but every time you make changes you must save the change as a .sql script file so any alterations are scripted.
Everything you do on your database will be done at least three times (once on development, once for testing and once on production). Change control is one of the most important processes to ensuring a stable database system.
Let's see how its done.
Modern Frameworks (EF)
Every change you do to the schema must be either saved in code or scripted out. We recommend using Migrations feature of Entity Framework. It allows you to keep track of all the changes in the similar fashion as SQL Deploy.

Figure: Example - SSW Rewards EF Migrations table Watch video: How to Use Code First with Entity Framework - Brendan Richards to learn more.
Legacy
Keep the scripts in a separate directory, this is often named
SQLScripts. This folder should only contain .sql files.- When you have an error you can see exactly which script introduced it
- You don't have to use a compare tool like Red-Gate SQL Compare at the end of your development cycle
- Your application can automatically make schema changes
- The application can have a "Create" database button when installed for the first time
- The application can have an "Upgrade" button and work out itself if this new version needs scripts to be run
- The application can tell if it is an old version (as a newer version may have upgraded the schema), so you only use the latest clients
- The application can have a "Reconcile" feature that compares the current schema to what it should be
File naming convention:
The script file naming convention should be as follows:
XXXXX_ObjectType_ObjectName_ColumnName_Description_SchemaMasterInitials.sqlExample:
00089_Table_OrderStatus_Status_ChangeFromBitToChar_AC.sql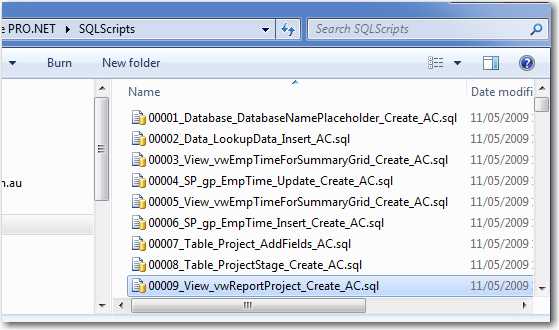
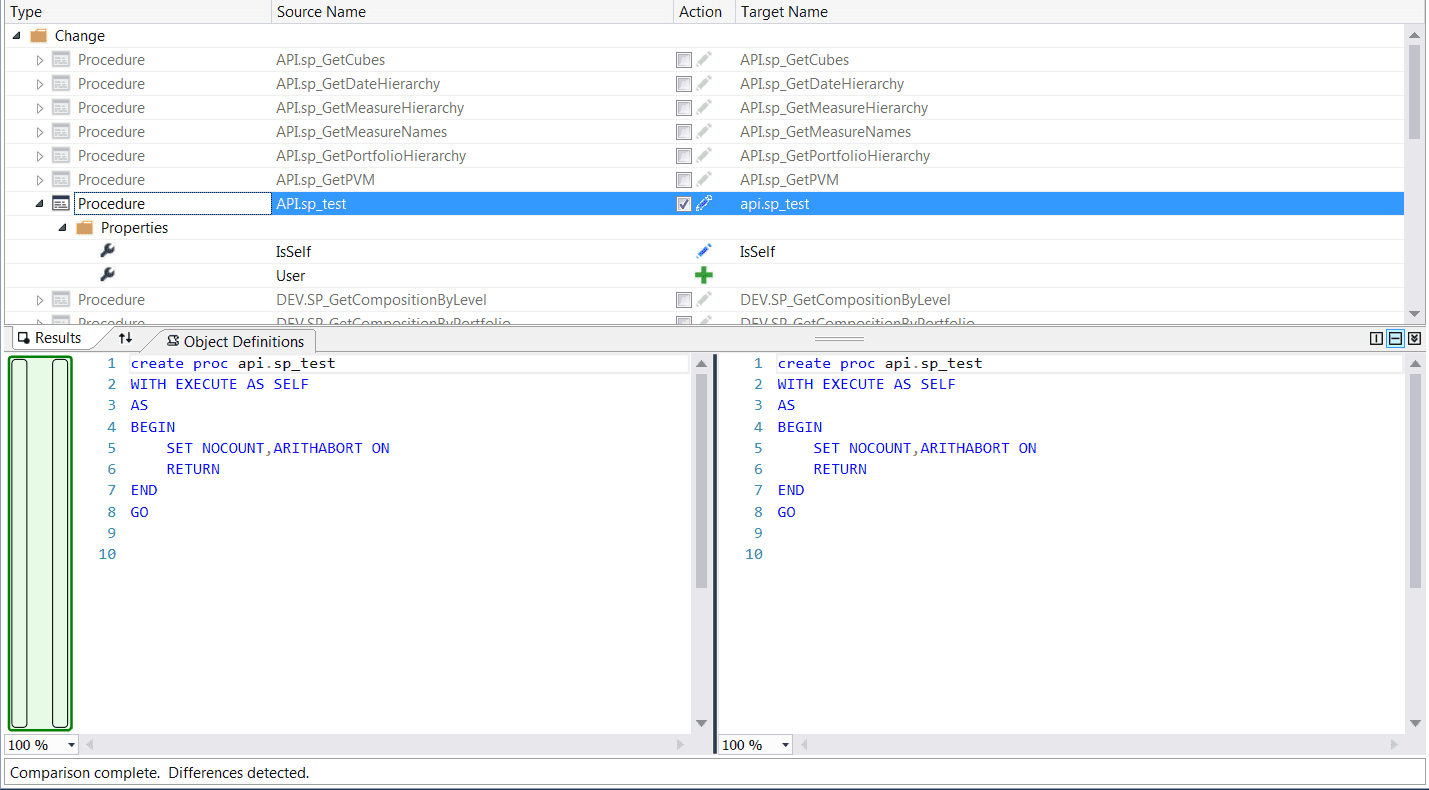
Figure: A list of change SQL scripts, each file name is in the correct format SQL Compare is a good tool to find out the differences between two databases. It can help you answer the question "Is your database the same as mine?".
However, if you are doing this at the end of your release cycle, you have a problem. Your schema deployment process is broken...
What you should be doing is seeing your Schema Master each time you have a new .sql file. You do this during the development process, not at the end in the package and deployment process.
Tip: If you are using modern methods such as Entity Framework code first migrations you will already be doing most of this.
Tools like Red Gates SQL Compare and Microsoft's Schema Compare (aka Data Dude) will compare schemas really well but aren't useful when you are deploying as it won't be repeatable.
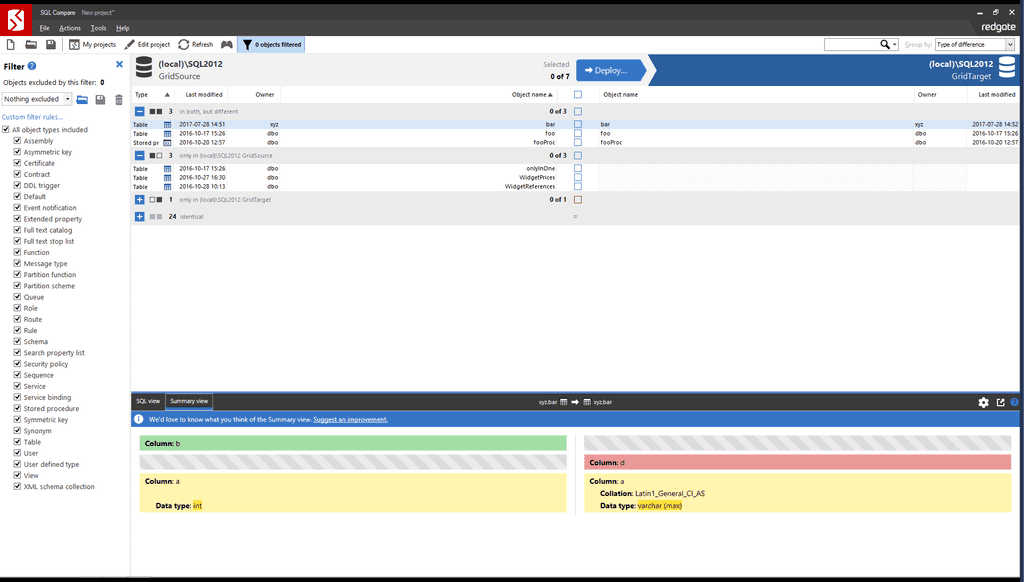
Figure: Using Red Gates SQL Compare 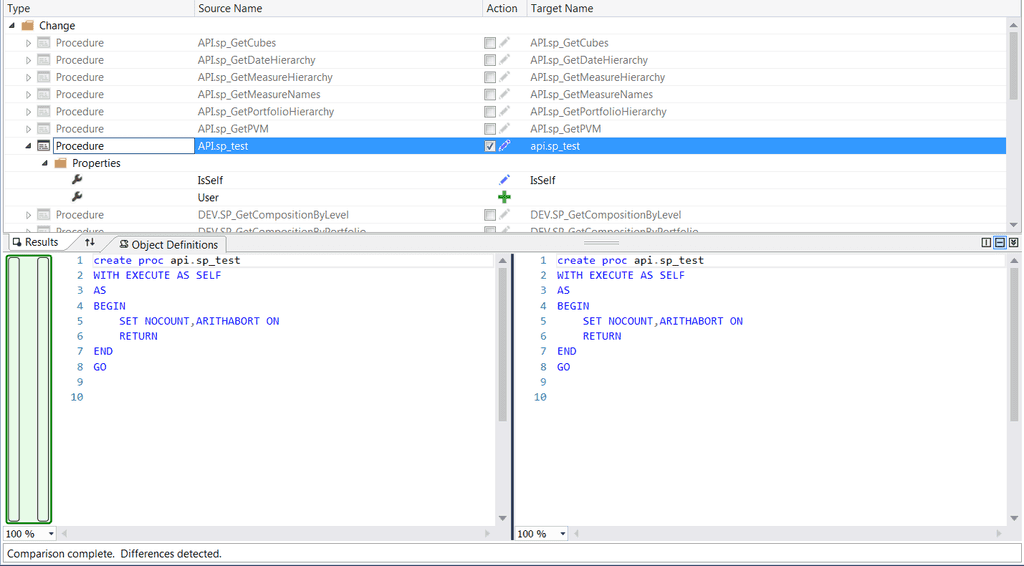
Figure: Using Visual Studio SQL Schema Compare An Application upgrade might not only include the .exe and .dll but the database changes. How to deploy these changes, manually or using tools to deploy?
Let's see the bad and good examples:
Dear Mr Northwind,
Before installing your application, you need to run this script by first opening up SQL Management Studio. Open the attached script, point it to Northwind and execute the script.
Let me know if you have any issues... We worked very hard on this release.
I hope you’re happy with it.
Regards, Dave
Figure: Bad example - run SQL scripts manually
Hi Mr. Northwind,
Please run the attached Northwind_v5.exe.
Click Run when the prompt appears.
Regards,
DaveFigure: Better example - run SQL scripts using another package
Dear Mr Northwind,
When you run the Northwind v1.0 (Rich Client) it will automatically upgrade the database for you.
Just make sure you have dbo permissions ⚠️
Let me know if you run into any issues.
Regards,
DaveFigure: Better example - run SQL scripts in the application. There is a tool called SQL Deploy | Reconcile
Dear Mr Northwind,
We have just deployed a new release and updated the database for you. Please view it live here.
If you have any questions please let me know.
Regards,
DaveFigure: Good example - All done as part of the release pipeline
Many developers worry about Idempotency. They make sure that their scripts can run multiple times without it affecting the database, upon subsequent running of the script.
This usually involves a check at the start to see if the object exists or not.
E.g. If this table exists, then don't create the table.Seems popular, seems like a good idea, right? Wrong! And here is why.
Database scripts should be run in order (into separate sequential files), as per the rule Do you script out all changes?
Therefore developers should not worry about idempotency, as the script will run in the order it was created. Actually, if they are doing this, then they want to see the errors. It means that the database is not in the state that they expect.
IF EXISTS (SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE='BASE TABLE' AND TABLE_NAME='Employees' ) ALTER TABLE [dbo].[Employees]( …… ) ON [PRIMARY] ELSE CREATE TABLE [dbo].[Employees]( …… ) ON [PRIMARY]Bad example – worrying about the idempotency should not be done, if you plan to run your scripts in the order they were created
CREATE TABLE [dbo].[Employees]( …… ) ON [PRIMARY]Good example – not worrying about the idempotency. If errors occur we don’t want them to be hidden + it is easier to read

Figure: Viagra isn't the cure to your Idempotency problems See the concept of Idempotence on Wikipedia
Controlled Lookup Data is when data is tightly coupled to the application. If the data is not there, you have problems. So how do we check to see if data is still there?
Let's look at an example, of a combo that is populated with Controlled Lookup data (just 4 records)
Modern Frameworks (EF)
With Frameworks like Entity Framework you can write unit tests to catch data issues before it becomes an problem.
Legacy Applications
With legacy applications, creating a stored procedure will have the same effect with a bit more effort.
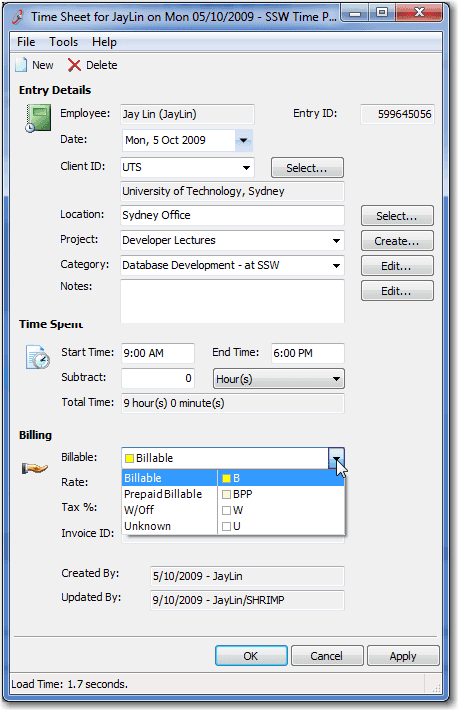
Figure: How do I make sure these 4 records never go missing? CREATE PROCEDURE procValidate_Region AS IF EXISTS(SELECT TOP 1 * FROM dbo.[Region] WHERE RegionDescription = 'Eastern') PRINT 'Eastern is there' ELSE RAISERROR(N'Lack of Eastern', 10, 1) IF EXISTS(SELECT TOP 1 * FROM dbo.[Region] WHERE RegionDescription = 'Western') PRINT Western is there' ELSE RAISERROR(N'Lack of Western', 10, 1) IF EXISTS(SELECT TOP 1 * FROM dbo.[Region] WHERE RegionDescription = 'Northern') PRINT 'Northern is there' ELSE RAISERROR(N'Lack of Northern', 10, 1) IF EXISTS(SELECT TOP 1 * FROM dbo.[Region] WHERE RegionDescription = 'Southern') PRINT 'Southern is there' ELSE RAISERROR(N'Lack of Southern', 10, 1)Figure: Implement a stored procedure to check the 'Controlled Lookup Data' does not go missing
Note: As this procedure will be executed many times, it must be Idempotent
Lookup data is data that you usually see in combo boxes. It may be a Customer Category, a Product Color or the Order Status. Usually this is defined by the user and the programmer does not care what or how many records they have. When the programmer relies on records being in the lookup table, it is called 'Controlled Lookup Data'.
So whenever you have special data, which is referenced in code you need to tread carefully by:
- First understanding that although most of the time there is a clear separation between data and schema, there is an exception for Controlled Lookup Data. This is when data (aka Controlled Lookup Data) is tightly coupled to the application, meaning that you have an application that cannot function correctly without that data.
- You need to deploy that 'Controlled Lookup Data'
- You then need to add a check for it so that it does not disappear.
Let's look at an example:
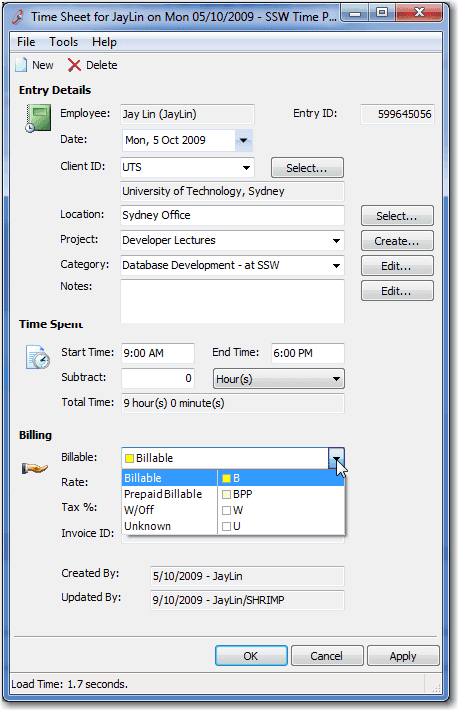
Figure: This combo looks innocent. However if it is "Billable" then the calendar goes yellow 
Figure: Billable days are shown in yellow if (drDay.NotBillableCount == 0 && drDay.BillableCount > 0) { //Yellow Background cell.BackColor = Color.FromArgb(255, 255, 140); cell.BackColor2 = Color.FromArgb(255, 255, 140); } else if (drDay.BillableCount > 0) { cell.BackColor = Color.FromArgb(255, 255, 140); cell.BackColor2 = Color.LightGray; } else { cell.BackColor = Color.LightGray; cell.BackColor2 = Color.LightGray; }Figure: This application has "Controlled Lookup Data" here, because if the "BillableCount" is greater than 0, the color shown will be yellow
Modern Frameworks (EF)
Entity Framework allows for Data Seeding which is the process of populating a database with an initial set of data. This is perfect for populating controlled lookup data.
Legacy Applications
For older applications, create SQL scripts like the example below.
INSERT INTO dbo.[EmpTimeBillable] ([CategoryID], [CategoryName], [DateCreated], [DateUpdated], [EmpUpdated], [Note], [rowguid], [Colour]) VALUES ('ALL', '', '09/13/2009 00:00:00', '09/13/2009 00:00:00', 'SSW-AdamCogan', 'Used for reports - Excluded in Timesheets and Tasklist data entry', '{A9A009A9-4E19-4FD3-B86A-B9260067D0EF}', 'White') GO INSERT INTO dbo.[EmpTimeBillable] ([CategoryID], [CategoryName], [DateCreated], [DateUpdated],[EmpUpdated], [Note], [rowguid], [Colour]) VALUES ('B', 'Billable', '07/01/2009 00:00:00', '07/01/2009 00:00:00', 'SSW-AdamCogan', 'DON’T CHANGE - These are hard coded', '{F410C25D-1F1A-4340-B7A4-7A4AAE037708}', 'Yellow') GO INSERT INTO dbo.[EmpTimeBillable] ([CategoryID], [CategoryName], [DateCreated], [DateUpdated], [EmpUpdated], [Note], [rowguid], [Colour]) VALUES ('BPP', 'Prepaid Billable', '02/28/2009 15:30:19', '02/28/2009 00:00:00', 'SSW-AdamCogan', 'DON’T CHANGE - These are hard coded', '{608AA6FF-B3C5-47BE-AC9A-29553E89643D}', 'LightYellow') GO INSERT INTO dbo.[EmpTimeBillable] ([CategoryID], [CategoryName], [DateCreated], [DateUpdated], [EmpUpdated], [Note], [rowguid], [Colour]) VALUES ('U', 'Unknown', '07/01/2009 00:00:00', '07/01/2009 00:00:00', 'SSW-AdamCogan', 'DON’T CHANGE - These are hard coded', '{74937D60-D2B2-4A4D-96AD-7F5B1941B244}', 'White') GO INSERT INTO dbo.[EmpTimeBillable] ([CategoryID], [CategoryName], [DateCreated], [DateUpdated], [EmpUpdated], [Note], [rowguid], [Colour]) VALUES ('W', 'W/Off', '07/01/2009 00:00:00', '07/01/2009 00:00:00', 'SSW-AdamCogan', 'DON’T CHANGE - These are hard coded', '{D51513CE-8A1D-41E4-93C4-3E827FF7522B}', 'LavenderBlue') GOFigure: This data must be deployed, just like we deploy a schema
Note: Now you need to add a test for your controlled data.
Check out Do you check your "Controlled Lookup Data" (aka Reference Data) is still there?
Scripting out a schema change is easy, worrying about data is not. "'Data motion" refers to a change in the meaning of data, which will require scripts which touch data and schema.
Let's look at an example:
We have a 'Gender' column (that is a Boolean) storing 0's and 1's. All works well for a while.
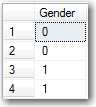
Figure: Anything wrong this Gender column? Later you learn you need to change the data type to char(2) to support 'MA', 'FE', 'NB' and 'NA'

Figure: Caster Semenya was the first to teach us a thing or two about the right data type for Gender The data then must be migrated to the new data type this way:
Rename 'Gender' to 'ztGender'Add a new column 'Gender' with type char(2) Insert the existing data from 'ztGender' to 'Gender' (map 0 to 'F' and 1 to 'M') Delete the column ztGender

Figure: Changing the data type and data required a "Data Motion Script" Note: zt stands for Temporary.
Visual Studio does not automatically support this scenario, as data type changes are not part of the refactoring tools. However, if you add pre and post scripting events to handle the data type change the rest of the changes are automatically handled for you.
Figure: Don't use Visual Studio Schema Compare Tool (aka Data Dude) Note: In order to achieve this you must use the built in Refactor tools as it create a log of all the refactors in order. This helps Visual Studio generate the schema compare and make sure no data is lost.
There are few options available to perform data type change correctly:
-
Use manual scripts. All data type changes including data migration can be performed by writing scripts manualy. This way you have full control over the change. It is recommended to use:
- DbUp to automate script deployment and keep track of all database changes.
- Use Database Project. As mentioned above, Visual Studio does not support data type changes out of the box and should not be used to perform this kind of task.
- Use Entity Framework (EF) Code First Migrations. If your application uses Entity Framework Code First, then it is strongly recommended to use Migrations feature.
Using EF Code First Migrations is comparable to using one of the below combinations:
- DBUp + SQL verify
- DAC Support For SQL Server Objects and Versions (.dacpac files)
- SQL Deploy
public partial class GenderToString : DbMigration { public override void Up() { AlterColumn("dbo.Customers", "Gender", c => c.String(maxLength: 2)); } public override void Down() { AlterColumn("dbo.Customers", "Gender", c => c.Boolean(nullable: false)); } }Bad Example - the default scaffolded migration will not perform any mapping of your data\
public partial class GenderToString : DbMigration { public override void Up() { AddColumn("dbo.Customers", "GenderTemp", c => c.Boolean(nullable: false)); Sql("UPDATE [dbo].[Customers] set GenderTemp = Gender"); DropColumn("dbo.Customers", "Gender"); AddColumn("dbo.Customers", "Gender", c => c.String(maxLength: 2)); Sql("UPDATE [dbo].[Customers] set Gender = 'MA' where GenderTemp=1"); Sql("UPDATE [dbo].[Customers] set Gender = 'FE' where GenderTemp=0"); DropColumn("dbo.Customers", "GenderTemp"); } }Good Example - Data motion with EF Migrations
-
Ideally you should be using computed columns as per Schema - Do you use computed columns rather than denormalized fields?
Many of the databases that SSW works with make use of denormalized fields. We believe this is with good reason. However, several precautions should be taken to ensure that the data held within these fields is reliable. This is particularly the case several applications are updating your denormalized data. To illustrate, let's say that we want to show all Customers with a calculated field totalling their order amount (ie Customer.OrderTotal).
With this example in mind, the main reasons we use denormalized fields are:
Reducing development complexity
A denormalized field can mean that all SELECT queries in the database are simpler. Power users find it easier to use for reporting purposes - without the need for a cube. In our example, we would not need a large view to retrieve the data (as below).
SELECT Customer.CustomerID, SUM (SalesOrderDetail.OrderQty * (SalesOrderDetail.UnitPrice - SalesOrderDetail.UnitPriceDiscount) ) AS DetailTotal, Customer.SalesPersonID, Customer.TerritoryID, Customer.AccountNumber, Customer.CustomerType, Customer.ModifiedDate, Customer.rowguid FROM Customer INNER JOIN SalesOrderHeader ON Customer.CustomerID = SalesOrderHeader.CustomerID INNER JOIN SalesOrderDetail ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID GROUP BY Customer.CustomerID, Customer.SalesPersonID, Customer.TerritoryID, Customer.AccountNumber, Customer.CustomerType, Customer.ModifiedDate,Customer.rowguid ORDER BY Customer.CustomerIDFigure: A view to get customer totals when no denormalized fields are used
If we had a denormalized field, the user or developer would simply have run the following query:
SELECT Customer.CustomerID, Customer.OrderTotal AS DetailTotal FROM Customer ORDER BY Customer.CustomerIDFigure: Queries are much simpler with denormalized fields
Note: that this is not a particularly complicated example. However, you can see why it can simplify development greatly when working with a large number of tables.
Performance is better for read-intensive reports
Particularly when reporting on data with a cube.
When there a multiple tables in a SQL Server view
They cannot be updated in one hit - they must be updated one table at a time.
It is a built-in validation device
For example, if records are accidentally deleted directly in the database, there is still a validation check for the correct totals. The value of this is mitigated when there is a full audit log on the database
However, there are reasons against using denormalized fields:
They have to be maintained and can potentially get out of synch
This can make them unreliable - particularly if several applications are incorrectly updating the denormalized fields. UPDATE, INSERT, DELETEs are more complicated as they have to update the denormalized fields
They can be seen as an unnecessary waste of space
All in all, we choose to still use denormalized fields because they can save development time. We do this with some provisos. In particular, they must be validated correctly to ensure the integrity of the data.
Here is how we ensure that this data is validated:
- Change the description on any denormalized fields to include "Denormalized" in the description - "Denormalized: Sum(OrderTotal) FROM Orders" in description in SQL Server Management Studio.
- Create a view that lists all the denormalized fields in the database - based on the description field.
CREATE VIEW dbo.vwValidateDenormalizedFields AS SELECT OBJECT_NAME(id) AS TableName, COL_NAME(id, smallid) AS ColumnName, CAST([value] AS VARCHAR(8000)) AS Description, 'procValidate_' + OBJECT_NAME(id) + '_' + COL_NAME(id, smallid) as ValidationProcedureName FROM dbo.sysproperties WHERE (name = 'MS_Description') AND (CAST([value] AS VARCHAR(8000)) LIKE '%Denormalized:%')Figure: Standard view for validation of a denormalized field
- Create a stored procedure (based on the above view) that validates whether all denormalized fields have a stored procedure that validates the data within them
CREATE PROCEDURE procValidateDenormalizedFieldValidators AS SELECT ValidationProcedureName AS MissingValidationProcedureName FROM vwValidateDenormalizedFields WHERE ValidationProcedureName NOT IN ( SELECT ValidationProcedureName FROM vwValidateDenormalizedFields AS vw LEFT JOIN sysobjects ON vw.ValidationProcedureName = OBJECT_NAME(sysobjects.id) WHERE id IS NOT NULL )Figure: Standard stored procedure for validation of a denormalized field
If you want to know how to implement denormalized fields, see our rule Do you use triggers for denormalized fields?