Rules to Better Backups - 10 Rules
Need help with Backup and Disaster Recovery Plan? Check SSW's Backups consulting page.
Business continuity is present in any good disaster recovery plan and means that when your services (e.g. websites, hardware, software) fail or suffer an outage, you have measures in place to ensure downtime is minimal.
Before diving further, some terms need to be understood to fully understand the concept of business continuity: Redundancy, High Availability, Fault Tolerance and Disaster Recovery. These are concepts used to ensure that a system has as little downtime as possible, by applying different strategies or actions in case of a fault.
Step 1 - Redundancy
Redundancy is a base concept that is applied to all other concepts e.g. High Availability and Fault Tolerance. Redundancy mainly means having extra hardware or software that can be used as backup (or in tandem) with the primary one e.g. having 2 virtual machines, one on-premises and one in Azure. When one fails, the other one can be used as the backup.
It's always a good idea to have redundancy on-premises and also in an off-premises (e.g. Azure) location, so in cases of any location disasters, you can rest assured your data and services are safe.
Let's imagine a scenario with the company Northwind, this is part of their infrastructure redundancy in their HQ server room:
- Power Redundancy - Two (or more) UPS on different electrical circuits powering the same servers
-
Backup Redundancy - Two (or more) backup servers on multiple physical locations:
- on-premises - e.g. a Data Protection Manager (DPM) server on Northwind HQ
- off-premises - e.g. a DPM server in Northwind Brisbane branch
- cloud - e.g. in Azure using Azure Site recovery and Azure Backups
- Hyper-V Redundancy - Two (or more) physical server blades as Hyper-V hosts
- Storage Redundancy - Two (or more) hard drives for the same data to be stored on
- Networking Redundancy - Two (or more) firewalls for traffic to go through
There are many ways to automate or apply redundancy, check the below for more information.
Step 2 - Fault Tolerance (FT) and High Availability (HA)
Fault Tolerance and High Availability work together to ensure maximum uptime, and will be mixed and matched depending on different systems and business needs e.g. FT works wonderfully for storage drives and RAID arrays, whereas HA is better suited for redundant Virtual Machines where you can't easily recover from a corrupted hard drive.
Fault Tolerance (FT)
This design enables systems to continue operating even if a fail happens - generally in a degraded or reduced state. There is no redirection of workload like in High Availability.
A good example is a RAID 6 array, where if two disks fail, you can keep using it without problems. If a third disk fails, then you lose the whole array - it can tolerate two faults, and is designed in a way that you can fix that fault and rebuild or recover the array to normal again and have no data loss.
Let's imagine the same scenario with the company Northwind, this is part of their FT plan:
- Storage Fault Tolerance - Local SAN (storage area network) in Northwind HQ, with multiple drives, where some drives can fail without interrupting its usage - giving time for the SysAdmin to swap said drives
High Availability (HA)
A high available system is one that is designed to be up and available as much as possible. Generally, this means that a secondary system, mirror of the primary, is also up and running at the same time as the primary, and if the primary system goes down, the secondary takes over as soon as it sees a fault in the first one - ensuring the system is online. Swapping to the secondary system might take a bit of time, and that adds to the time the system is down.
Let's imagine the same scenario with the company Northwind, this is part of their HA plan:
- Power High Availability - Two (or more) UPS on different electrical circuits powering the same servers with a load balancer that sees one failed and uses the power from the other
- Hyper-V Redundancy - Two (or more) physical server blades as Hyper-V hosts part of the same failover cluster - if one blade goes down, VMs are automatically migrated to another host in the cluster
- Networking High Availability - Two (or more) Firewalls working on an active-passive state - one takes over if the other fails
- Software High Availability - Two (or more) webservers behind a load balancer - they can share the website traffic at the same time, or be in an active-passive state as above
For HA, one of the key points is having a system that redirects workloads in case of a failure - without that, you might have a redundant system, but not necessarily high available. If you need to manually swap a cable in case of a power failure, that's just redundant but not high available.
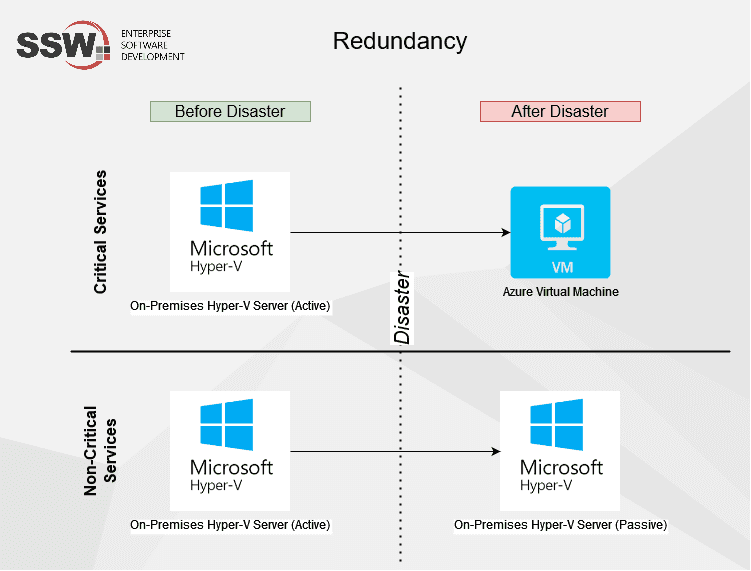
Figure: Good example - It's crucial to add a redundancy plan to your disaster recovery plan Step 3 - Disaster Recovery (DR)
A good DR plan consists of HA and FT together and goes beyond only having the above strategies in place - it actually tells you what to do in case of a disaster e.g. natural disasters like eartquakes, cyberattacks or any other cause of downtime.
DR plans generally show different scenarios or systems and what to do in each case e.g. lost a critical system, lost a non-critical system.
As an example, if one of the UPS in your server room stops working, that might not impact the day to day of your business if you have a secondary UPS and a HA circuit or system that automatically fails over between them - you need to replace the failed device, but no downtime is felt throughout the business.That might not be the case if your UPS fails, you have a secondary UPS, but you need to manually failover to the secondary. Your server room will be all offline until you manually change that cable, and that action should be in the DR plan in the case of a UPS fail.
A good example of business continuity tools is Azure Site Recovery.
Backups are also important in your business continuity and disaster recovery plan, check out our other Rules to Better Backups.
Azure Site Recovery is the best way to ensure business continuity by keeping business apps and workloads running during outages. It is one of the fastest ways to get redundancy for your VMs on a secondary location. For on-premises local backup see Do you know why to use Data Protection Manager?
Ensuring business continuity is priority for the System Administrator team, and is part of any good disaster recovery plan. Azure Site Recovery allows an organization to replicate and sync Virtual Machines from on-premises (or even different Azure regions) to Azure. This replication can be set to whatever frequency the organization deems to be required, from Daily/Weekly through to constant replication.
When there is an issue, restoration can be in minutes - you just switch over to the VMs in Azure! They will keep the business running while the crisis is dealt with. The server will be in the same state as the last backup. Or if the issue is software you can restore an earlier version of the virtual machine within a few minutes as well.
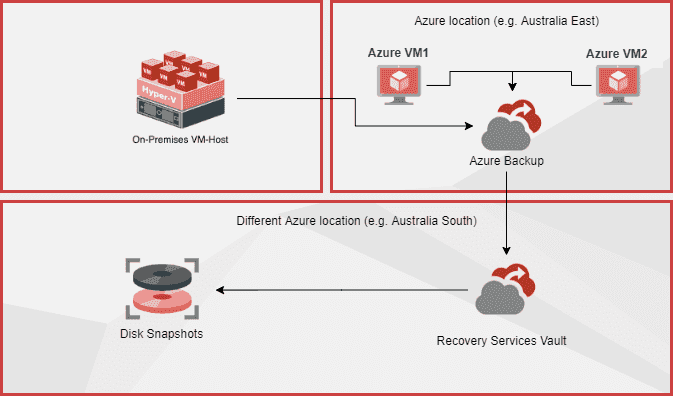
Figure: Azure Backup and Site Recovery backs up on-premises and Azure Virtual Machines At some point every business will experience a catastrophic incident. At these times it is important to have a plan that explains who to contact, the priority of restore and how to restore services.
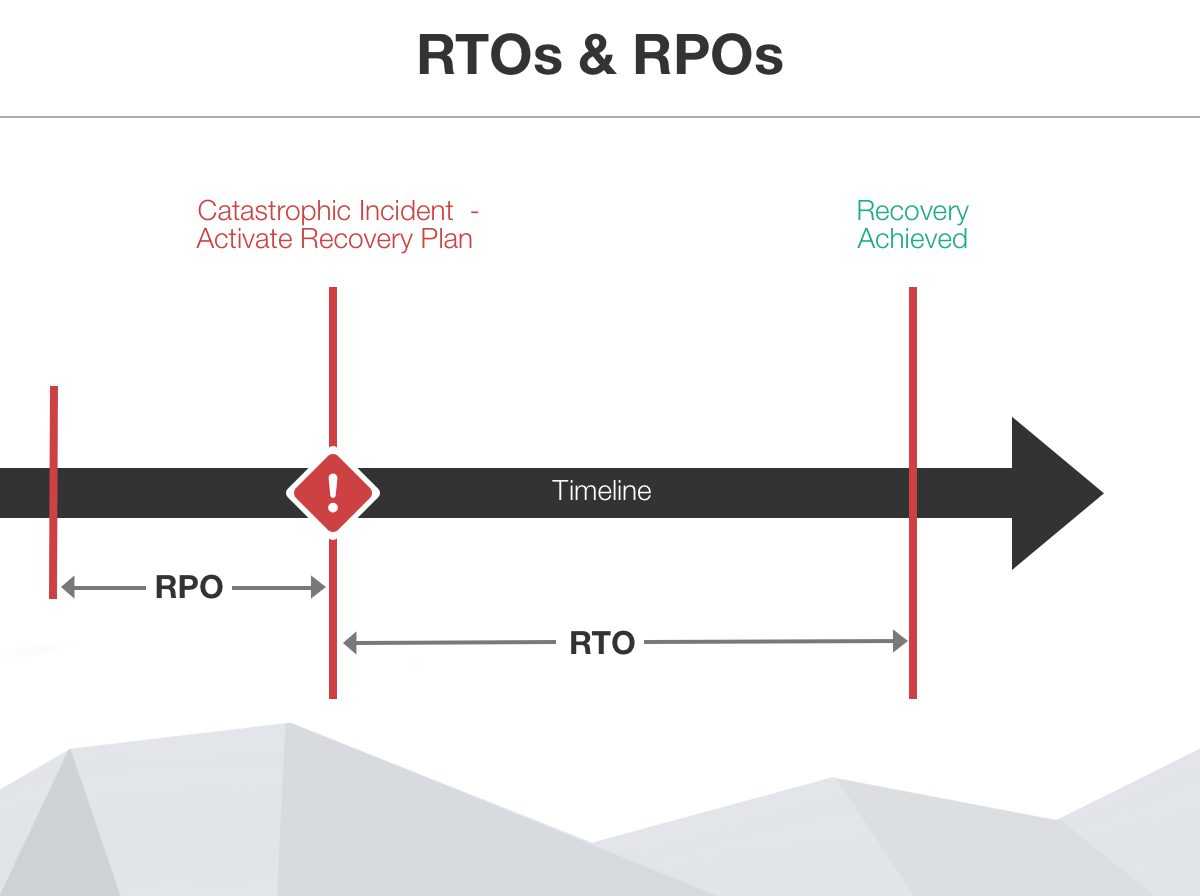
At the time of a disaster, you should have a few objectives established and measure some results - The objectives are RPO (Recovery Point Objective) and RTO (Recovery Time Objective); and the measurements to take are RPA (Recovery Point Actual) and RTA (Recovery Time Actual).
It's recommended to practice your disaster recovery at least once every 12 months. This way you make sure that you are investing in the minimum amount of required resources, and that your plan actually works.
So what do these terms mean?
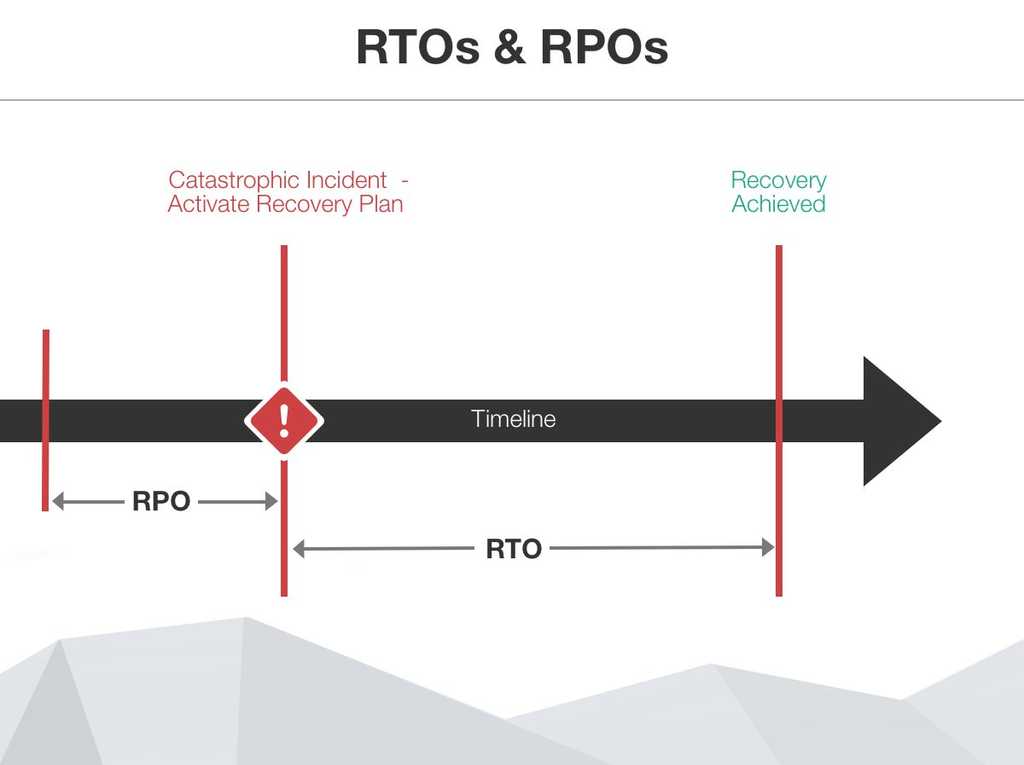
Figure: RTO's vs RPO's RPO
RPO or Recovery Point Objective, is a measure of the maximum tolerable amount of data that the business can afford to lose during a disaster. It also helps you measure how long it can take between the last data backup and a disaster without seriously damaging your business. RPO is useful for determining how often to perform data backups.
RTO
RTO or Recovery Time Objective, is a measure of the amount of time after a disaster in which business operation is retaken, or resources are again available for use. This measurement determines the amount of resources that are required for the recovery to happen within the timeframe required.
RPA
RPA or Recovery Point Actual, is the actual measurement of the amount of data lost during a disaster recovery.
RTA
RTA or Recovery Time Actual, is the actual measurement of downtime during a disaster recovery.
Note: these may all be different for different services. For example at a bank you may have a transaction database, this may need to be only ever able to experience a RPA\RTA of a few minutes as even in that few minutes, thousands of transactions could be lost. However the same bank may have a website that they are happy to have an RTA\RPA of several hours as this is much less critical to the banks overall operation.
How to calculate these values?
RTO and RPO are determined via a consultation called BIA (Business Impact Analysis). The organization needs to work out what the maximum amount of data that they are prepared to lose and also the maximum amount of time that they are prepared to be without services. These are both measured in time, and could be seconds, minutes, hours or days depending on the organization's requirements. This is a balancing act as generally the shorter the timeframe required, the more resources the organisation will need in order to achieve the target.
After this a disaster should be simulated to test that the RTA/RPA values match the RTO/RPO required by the organization.
Example: Mr Bob Northwind experienced a catastrophic incident. The failure occurred at 8pm local time on a Friday night. Their website and sales transaction software were affected.
In his Disaster Recovery Plan he had the following objectives:
Service RPO RTO Northwind Website 2 days 4 hours North Sales 4 hours 8 hours It is important that these objectives are signed off by the Product Owner as per this rule
After the recovery was complete they then analyzed the downtime which showed the following:
Service RPA RTA Northwind Website 8 hours 2 days North Sales 8 hours 8 hours After analyzing the data, they discovered a few issues with their Disaster Recovery Plan:
- They didn't have any spare hardware on premises which meant that to get the website backed up and running they needed to find a shop on a weekend to buy a server and then start the recovery process. This delayed them by an entire day.
- Mr Northwind's IT Manager had mistakenly set the backups to 12-hour backups (at midnight and midday each day). This meant that the most recent backup for both services had occurred at 12pm on Friday and they had 8 hours of missing transactions. The greatest allowable data loss should have only been 4 hours.
This explains why it is important to practice your disaster recovery plan. A real incident is not the ideal time to realize that your backup/procedures are inadequate.
Using Data Protection Manager (DPM) to backup your servers.
You can read more about DPM by clicking here.
There are many options for personal and business backup solutions on the market.
OneDrive
OneDrive from Microsoft is a simple and powerful application to do your cloud backups, for free. It is pre-installed on both Windows 10 and 11.
Size: 5GB free
OneDrive for Business (Recommended)
OneDrive for Business shares its name with OneDrive, but gives a different product. This service is paid but gives you a good return for your investment. OneDrive for Business comes with Office 365, so it is much more suited for business who already have a subscription of the service, or who need to more control over the backups and files. OneDrive for Business uses the SharePoint structure (differently from OneDrive) to give users much more storage space than the normal one.
Size: 1TB free - If you have an Office365 business license. This option gives the best visibility for SysAdmins.
Dropbox
Lots of users use Dropbox because of its easy-to-use interface and amount of storage space. The service is pretty similar to Google Drive and works well in any environment.
Size: 2GB free
Google Drive
Google Drive is Google's solution to cloud backup and storage and works well. You have quite a lot of space for free, and it works even better if you are already using Google's ecosystem of software and services.
Size: 15GB free
Backblaze + MSP360 (was CloudBerry)
Backblaze offers good prices and reliable cloud backups for servers and personal. For personal, you have unlimited storage (paid per computer) after installing the Backblaze client in your computer - install and you are done! You can trust that your whole computer is backed up.
For servers, MSP360 Backup is the application of choice installed in each server, and Backblaze is the storage provider, managed inside MSP360 Backup. This is the choice for offsite backups in your disaster recovery solution.
Size: No free option
All services work very well and you can mix and match, and use them all together if you want to.
In today's digital landscape, the importance of robust email backup solutions cannot be overstated. Regular and efficient backups are essential, not just when an employee departs from the company, but on a daily basis to ensure data integrity and continuity. If you are using Microsoft's Exchange Online solution for your emails, these are some options for you.
Exporting PSTs Manually via Microsoft Purview
Waiting until an employee leaves the company and then manually exporting their PST files to a file server is inefficient and risky. This method is time-consuming, prone to errors, and does not guarantee data integrity or easy accessibility.While Microsoft Purview's Compliance center is good and allows you to export and search a lot, it's not the recommended way to back up your emails.
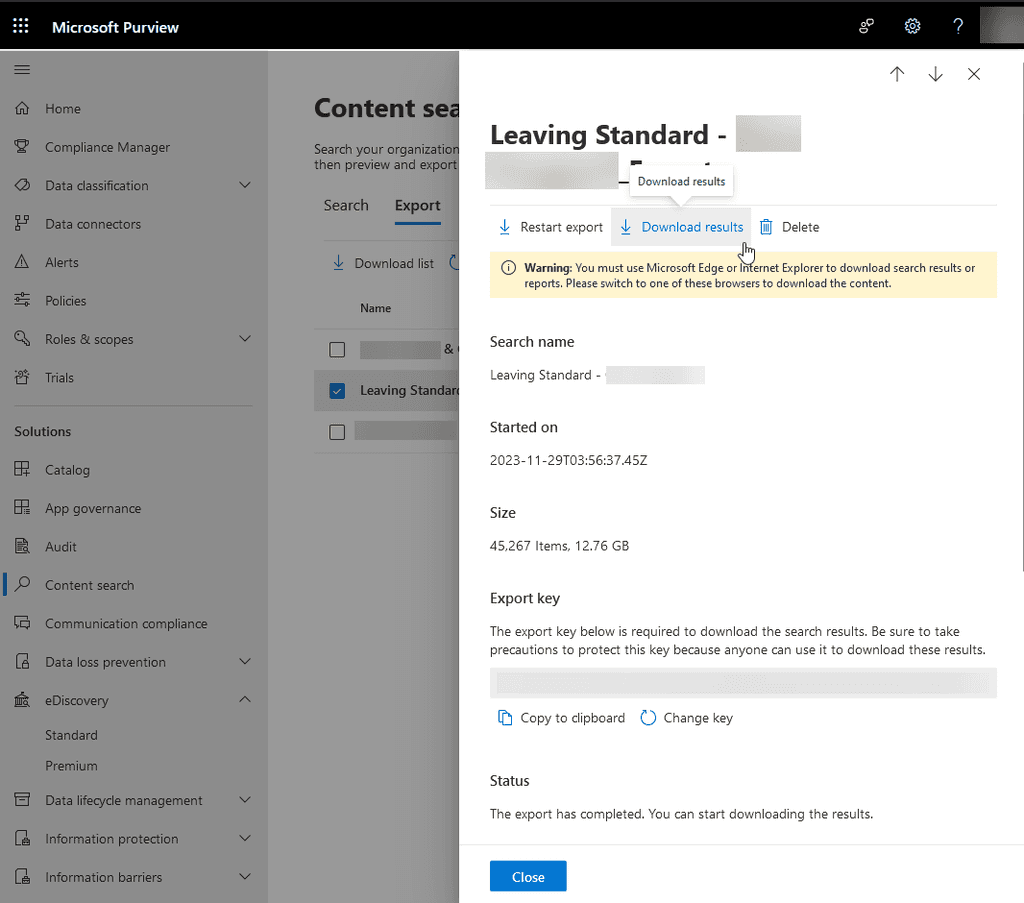
Figure: Bad example - Manually exporting PSTs is prone to errors Using a 3rd party Backup Solution
For reliable and efficient email backups, several third-party solutions are available in the market. Here are some notable options:
- N-Able by Cove Data Protection (Recommended): Offers comprehensive backup options for Exchange, SharePoint, and OneDrive. N-Able allows for efficient data backup and easy restoration with just a few clicks, ensuring high data protection and accessibility.
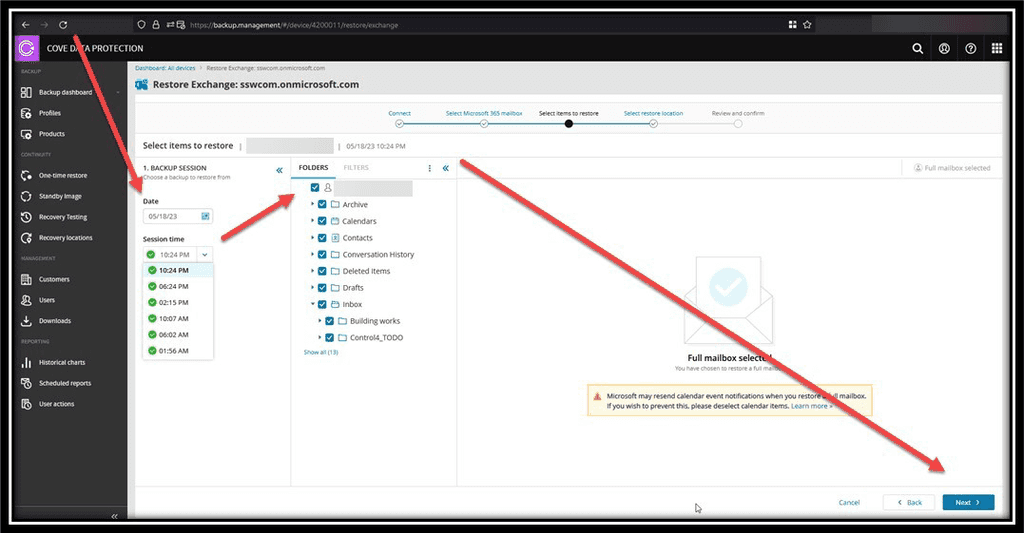
Figure: Good Example - An automatic, cloud-based backup solution takes snapshots of your data daily and makes it very easy to recover and restore any emails Other notable options:
- Veeam Backup for Microsoft Office 365: Provides secure backup for Office 365 data, including emails, with quick recovery options. It ensures that you have access to your email data in case of accidental deletion, security threats, or retention policy gaps.
- Acronis Cyber Protect: Known for its integration of backup with cybersecurity, Acronis Cyber Protect offers not only backup solutions for emails but also advanced security features to protect against malware and phishing attacks.
- Barracuda Cloud-to-Cloud Backup: Specializes in protecting data in cloud environments. Barracuda offers comprehensive backup and recovery solutions for emails in Office 365, providing protection against data loss and downtime.
Using a standard file structure for storing user data on laptops makes locating the important information fast and performing automated backup operations easy - Use this checklist.
Remember, the expectation is for all the questions to be answered with "YES" by the end of this checklist.

Domain-joined checklist
1. Is your computer domain-joined? {{ YES/NO }}
Note: To check, go to File Explorer | This PC | Right-click | Properties | Check for "Domain" or "Workgroup". If it says "DOMAIN", you are on the domain. If it says "WORKGROUP", you are not.2. The Backup Script - Date Last Run: {{ DD/MM/YYYY }}
If your computer is domain-joined, then your backup script should already be working (E.g. Daily at 11 am)
Go to the logs, e.g. File Explorer | Fileserver | UserBackups | ztBackupScripts | UserLogs.log to see the last time your backup was doneNon-domain-joined checklist
1. Do you use a cloud backup application? {{ YES/NO }}
Which one? {{ CLOUD APP }}Tip: Some good options include OneDrive for Business and Dropbox. You should always keep important files in the cloud for security reasons.
2. Do you keep your files in one folder structure? {{ YES/NO }}
Location: {{ LOCATION }} Size: {{ USED }} GB of {{ TOTAL }} GB Errors {{ NUMBER OF ERRORS }}Note: For OneDrive the default is: C:\Users[UserName]\OneDrive
Tip: You can have additional accounts in the same PC! (Even multiple OneDrive accounts)
Warning: If you are using OneDrive, it is not possible to change the root directory folder name. Normally, the root directory folder has a space in it ("OneDrive - SSW"), so keep that in mind when trying to run script or code from the OneDrive folder.
When you choose a location in OneDrive, it will always create the main root folder called "OneDrive - (YourOrganization)". Use this folder to store your files.E.g. Create a folder with your username in the root of C: prefix the folder with Data, for example, "C:\DataKaiqueBiancatti", and choose that folder to be your main OneDrive folder. It will automatically create a new folder inside it:
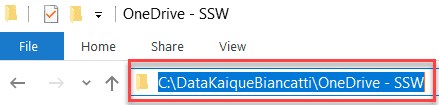
Figure: Good example - Location of Data{{ YourUserName }} with OneDrive - {{ YourOrganization }} folder in it 
Figure: Good example - Backup is being done automatically 3. Do you keep your desktop clean? {{ YES/NO }}
Number of files on Desktop (Aim is zero) {{ NUMBER OF FILES }}You should always aim to have a clean desktop, without temporary files or unnecessary shortcuts.Delete anything that is not necessary from there and do not save things there by default. Having a messy desktop just makes everything confusing.
4. Do you keep your Outlook PST/OST separated from your cloud backups? {{ YES/NO }}
Tip: You can check where your PST/OST is via Outlook | File | Account Settings | Data Files.
Note: By Default it is in C:\Users[UserName]\AppData so it is not backed up.
Outlook mailboxes tend to get huge in size pretty quickly, and your emails are already being backed up by your Exchange Server, so there is no need to back these files up. PST files (Outlook 2013 and earlier) contain all your mailbox messages and OST files (Outlook 2016 and newer) contain all your messages to be used offline.
5. Do you have a Temp folder? {{ YES/NO }}
Create a temporary folder for temporary files, like "C:\temp". It makes it easier to see.6. (Optional) Phone - Can you see the files that are on your PC on your mobile too? {{ YES/NO }}
Install the OneDrive (or your other selected backup application) app on your phone and log in with the same account you used on your PC.7. (Optional) Phone - Do you care if you lose your photos? {{ YES/NO }}
If not, why? {{ REASON }}
Which phone? {{ IOS/ANDROID }}
Which backup application are you using? {{ BACKUP APP }}
- If Yes and iOS, then use iCloud, OneDrive or your selected backup application on your phone to back them up automatically.
- If Yes and Android, then use Google Drive, OneDrive or your selected backup application on your phone to back them up!
- If you don't care about losing your photos, do nothing!
For any kind of backups, it is important to log a record on success so you can check for backups that have failed.
Without some kind of logging e.g. on a SQL database, on a txt file, on a SharePoint list, it is impossible to tell which backups have been completed or not. This applies to backups of any kind e.g. servers, personal computers, emails.
Some important stats to log:
- Date - Date backup has run
- Username - If a personal backup, which user was logged in when the backup ran
- PC Name - The name of the server (or PC) the backup came from
Having entries logged in a database is better than having an email sent because entries are easier to see and manage, and emails might get lost in the noise.
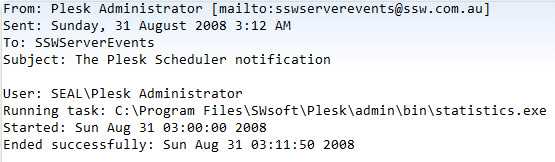
Figure: Bad example - an email is sent on completion 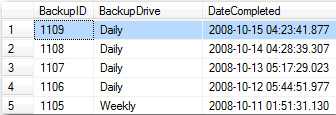
Figure: Good example - a record is logged on completion 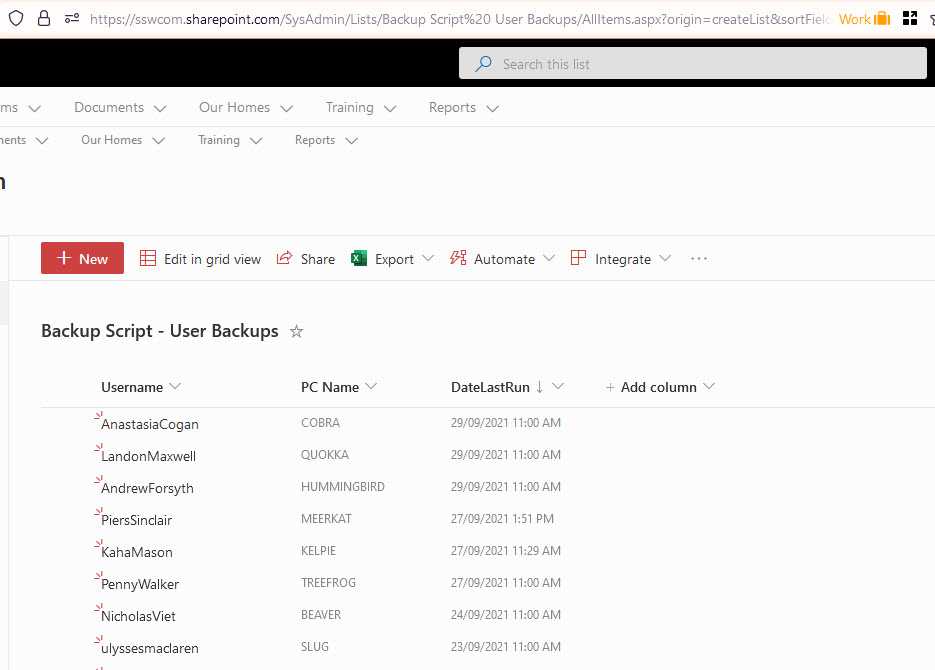
Figure: Best example - the latest completion is logged in a SharePoint list Now you are able to be aware of missing backups. You can make automatically notifications based on the above table e.g. by SQL Reporting Services data-driven subscription
It is also important to review the state of your backups at least on a weekly basis, ensuring that backups are not failing and that you are able to restore them when necessary. This is part of a good disaster recovery process.
To see the best backup tools currently available, check https://www.ssw.com.au/rules/pc-do-you-use-the-best-backup-solution
If you need any help with your backups or disaster recovery process, check https://www.ssw.com.au/ssw/Consulting/Backup-Recovery.aspx
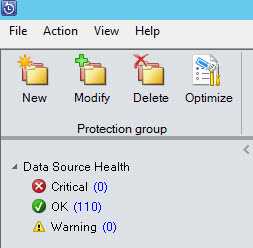
Figure: Good Example - No critical or warnings in your backups It is important to back up your work regularly to a separate location to prevent any loss of data. Ideally, back-ups are saved to a server or cloud-based file storage for ease of access.
When building projects, ensure that files and folders are labeled clearly and consistently. For example, use different folders for different file types - footage, images, exports, projects, etc. This ensures that another team member (or your future self) can easily find all the assets associated with the project. File names and structure should be consistent – both among team members and over time.
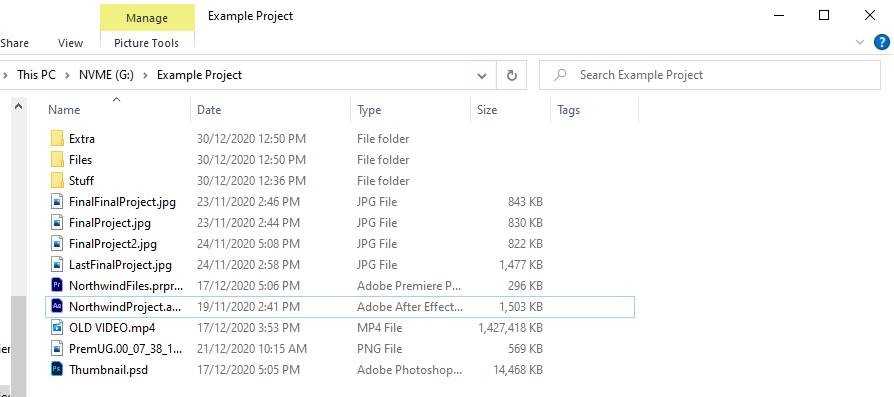
Figure: Bad example - The project is messy, without any meaningful or specific labels 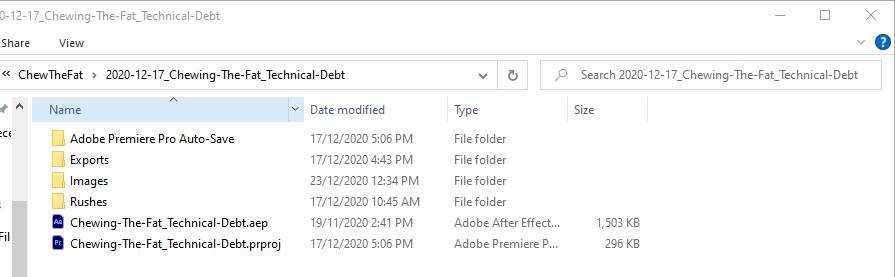
Figure: Good example - Folders are clearly labeled, the root file also includes the date A good file structure should also include storing finished projects separately from the working files. In a team environment, this system can also incorporate file ownership with different users.
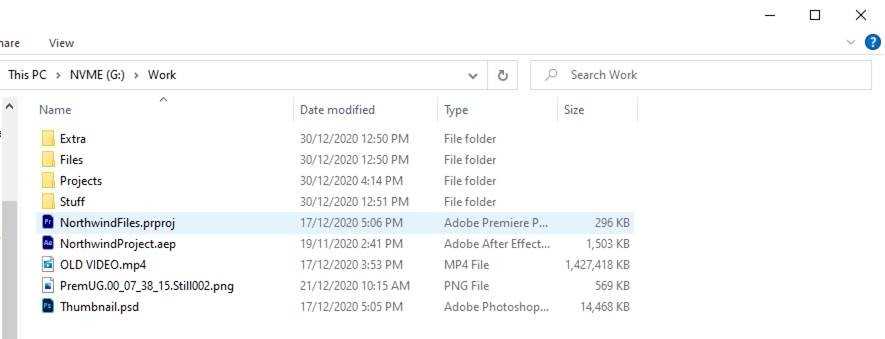
Figure: Bad example - A singular project folder, with some project, files also sitting outside it 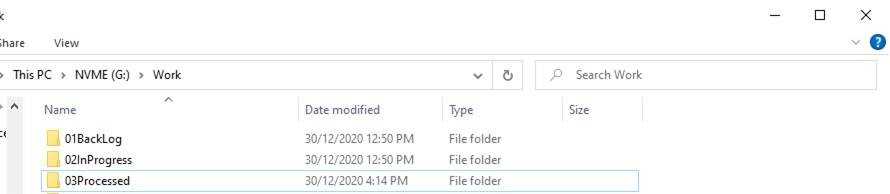
Figure: Good example - There are dedicated folders for projects that are in progress and completed File names are also very important - they are the principal identifier of a file. They need to include information about the content and context of the file.
Always use version numbers when saving – don’t use the word ‘final’. It is much easier to follow the progression of a project with numbers, both to find the latest version or to revert back to a previous one if needed.
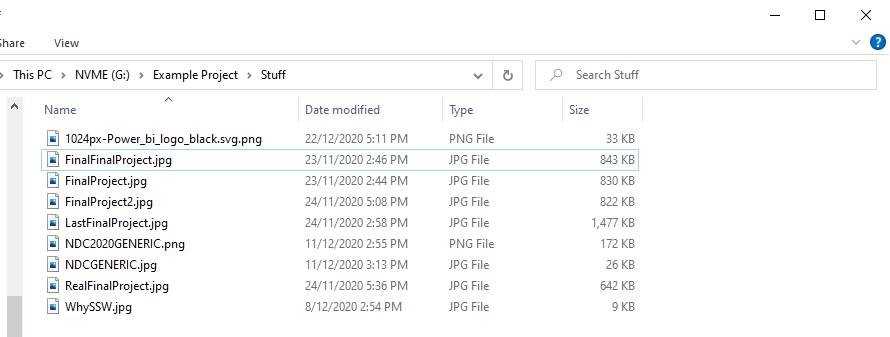
Figure: Bad example - Items are not named clearly and it is difficult to know what file is the correct export 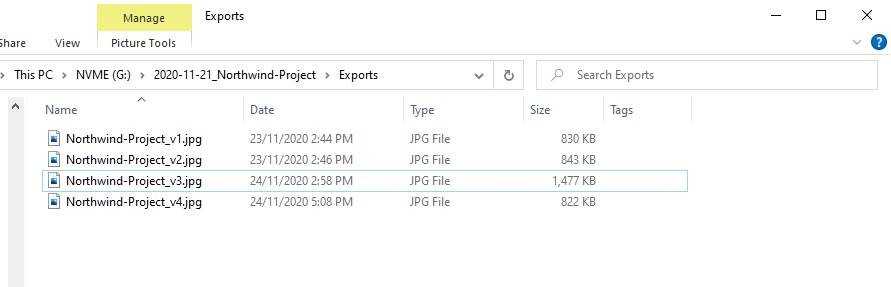
Figure: Good example - Each file has an appropriate version number Check "Always keep on this device" so you can access your files offline.
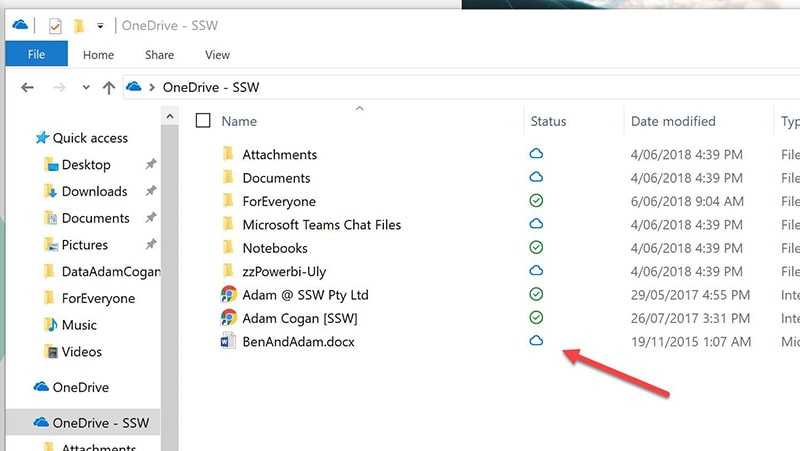
Figure: Bad example - By default you cannot open your files when you have no internet 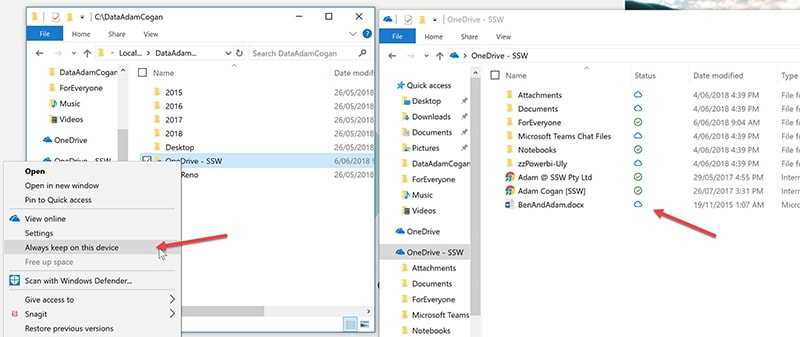
Figure: So check "Always keep on this device" 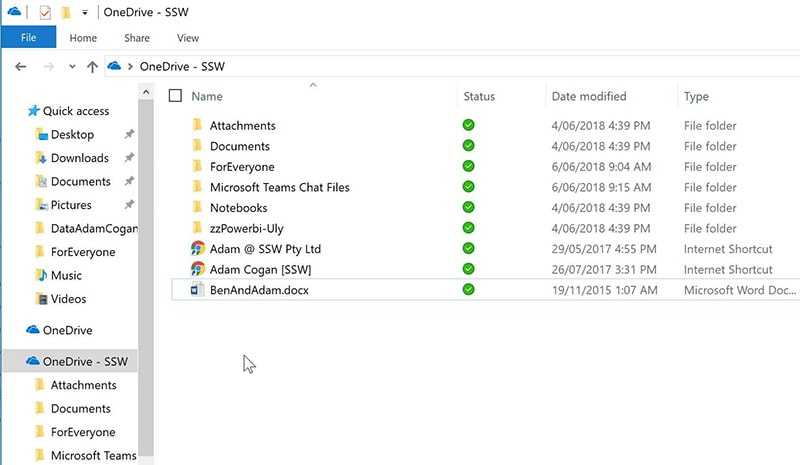
Figure: Good example – you can now open offline